
At the same time that I’ve been doing the literature research for this project, I’ve also been conducting a short term longitudinal study of social and informational networks as they develop among the entering first-year students of the Class of ’04 and the rest of the Bennington College community. I had several reasons for wanting to do this. Throughout this work I have been discussing and suggesting conceptual frameworks for thinking about information in social networks. My hope was that doing this kind of study might give me some real data for comparison – a qualitative check on how well theory actually describes what is going on. Ideally a network study of the campus might give me a baseline idea of the social structure of Bennington which could be built upon in future work. At the very least, attempting to construct and implement a study would teach me a great deal about methodologies and the complicating factors which will inevitably crop up when dealing with theory and data in the real world.
The Bennington College community and the entering class are an interesting subject for several reasons. For one, Bennington College is small enough that most of its members are known to each other (although that may be changing somewhat as the size of the student body increases). It is also in a sense fairly well bounded – there are formal categories of institutional membership as well as a strong consensus on who is part of the community. Although this certainly doesn’t eliminate the important theoretical problems of defining the boundaries of a social group, there is at least a relatively unambiguous operational definition of membership.
But my intuition is that the students here would show up as a “distinct social group” under a wide variety of definitions. The Bennington student community seems to display an unusual degree of isolation. Nearly all the students live in campus housing, the campus is located outside the town of Bennington, the majority of social activity takes place on campus – it is rare for students to hang out in off-campus bars, etc. Many students do not own vehicles, and there seems to be a strong tendency for them to remain on campus for large segments of the 14 week term. When there is contact with individuals in the surrounding community, it is usually of a functional rather than social nature – interactions with clerks at the grocery and liquor stores for example. Furthermore, nearly all of the students are on the College meal plan, and eat three meals a day together in the same dining hall. All of these factors argue for a situation in which a huge proportion of students’ interactions will be with other members of the college community18. Another advantage of Bennington is that the size of the College is small enough that some of the comprehensive survey methods for investigating social structure are quite feasible. At the beginning of the term in which I conducted the study, the number of registered students was 545, including a total of 28 in the MFA, MAT, and Post-Bac programs.
The event of a new class entering is also interesting for several sociological reasons. Most entering students arrive at Bennington (or any college) knowing almost none of their new peers. Furthermore, they are usually separated from their original (home) community social connections to a large degree. Although accepted as perfectly normal, this situation is pretty unusual. For most of us, arriving at college is one of the few times in our lives when we are able to construct an entire social network entirely from scratch, free from the direct influences of our parents and our social history. Perhaps this is part of what makes college such an exciting and scary experience. As I mentioned in the section on social networks, it is often the case that people meet others through people that they already know, creating an overlapping network of friend’s friends. But students arriving at Bennington come from communities all over the world, and may not have any second-step social ties in common with their new peers (this in itself is an interesting question to investigate.) Yet despite all of this, people seem to establish themselves and become oriented and connected very quickly. This makes the entry into college a fairly unique opportunity to track the growth and spread of social structure – provided an appropriate methodology can be developed.
Aside from an academic interest in the process of network formation and information transmission, I’m also curious about what it might say about Bennington in particular. How quickly and thoroughly are the freshmen integrated into the ‘culture’ of the school? How “cliquey” is Bennington? How does the social structure evolve over time? Do contacts made in orientation groups persist? Are houses or hobbies more important in determining who people socialize with? What demographic variables are predictive? It is hard to imagine that any kind of study could provide definitive answers about a place as diverse and rapidly changing as Bennington, but looking at these kinds of questions with some objective data is likely to provide some interesting insights.
But I’m especially interested in trying to examine the structure of the communicative networks among community members. Do people’s self descriptions of who they talk with and get information from reflect the “collective” conception of the organizational structure, or are they independent of it? How well integrated are “official” information channels (House Chairs, various administrative offices) into the actual network of people to whom we go to with questions? Are there “central” individuals who everyone knows and talks to? Who are they? Are there aspects of the geometrical structure of social connections which might give clues about the institution’s quirkiness?
My plan was to administer a social network survey to all of the first year students three times during their first term at Bennington. The first would hopefully take place as close as possible to the beginning of term (within the first couple of days) and the last would take place towards the end of term. The survey would take advantage of the known-membership aspect of Bennington. Each first-year would be given a multi-part, random-ordered list of everyone at Bennington, including faculty, administration, and upperclassmen (600-700 items) They would first be asked to indicate all of the names on the list which they recognized. Withen this subset they would be asked to indicate people with whom they have spoken.. This would be repeated, with questions asking about weekly and daily conversations. The survey would also collect some demographic information.
Obviously, the demons are in the details, and many of the specifics changed as I began dealing with the various technicalities and practicalities of implementing the study. To facilitate collection and the on-the-fly generation of the random name lists and the subsets which are specific to each person, I decided to make the survey questionnaire computer based, accessible as a JavaScript program running on a web site. One advantage about doing a web-based survey is that respondents can be simultaneous or asynchronous, so I wouldn’t need to worry about coordinating schedules. It also meant that I could collect some temporal data as well. But I was also concerned that I might get a fairly low response rate because the medium might be unfamiliar to some, and I was asking people to do the survey on their own time. I decided that I would initially notify people with a letter, and follow up with phone calls to non-respondents. The admissions office kindly agreed to distribute a letter containing a brief description and the web address for the study to each of the 1st-year’s mailboxes.
The survey was structured as follows: The Dean’s office provided me with a list of all the currently enrolled students and their class status.19 Each of the names was assigned a unique study-specific ID number. I included in the survey all of the incoming freshmen (167 names, class status of 0) and a randomly chosen sub-sample of the upperclassmen (73 names, or ~%20). I also included 10 names (chosen at random from an email petition) that were not members of the Bennington community to use as a control. There are obvious disadvantages to using only a sub-sample of upperclassmen and eliminating the faculty and administration names from the study, but the 250-item survey I used took ~10 minutes to complete and I was concerned that any additional names would increase non-response due to fatigue and boredom.
Upon logging onto the study site, respondents were shown a brief description and explanation of the study, presented with a link to obtain more information, and given the following instructions:
This survey is one of a class of surveys called Network Name Generators. I have implemented it as a web page to try to make it simpler, faster, and easier for both you and me.
– You will not be asked to provide any sensitive information.
– The information you provide is for the purpose of this study only and will be kept confidential.
– Your name will not appear in any paper or report, unless you give me explicit permission to use it
The survey is divided into five sections:
The first asks for fairly standard background information, such as your name and age, but also for information on what house you live in and what classes you are taking. You will be asked to provide contact information (phone or email). This is in case you do not complete part of the survey, or I need to contact you with questions.
The second part of the survey is the longest. A very large number of names will appear on screen one at a time. For each name you will be asked to click a button indicating whether the name is familiar to you. There are 250+ names, so you will want to work as quickly as possible. If you make a mistake, you can use the “GO BACK” button to return to the name and make the correction.
The third and fourth sections are very similar and will not take nearly as long (depending on how many names you are familiar with). All of the names which were familiar to you in Part II will appear in random order, and you will be asked how often you have conversations with each person.
Finally, you will be given a chance to comment on the survey and provide some suggestions.
If you are ready to begin the survey, please click the link below. Otherwise, please contact Skye Bender-deMoll with questions or concerns. [phone: x4110 email: skyebend@bennington.edu]
If the respondent clicked the link labeled “I have read the instructions and give permission for my information to be used in this study,” they were taken to a page containing a form for entering demographic information. When that was completed, they were taken through the name recognition process as described in the instructions. Upon completion they were thanked, and the formatted data from the survey, including a time stamp and other data, was automatically emailed to me.
The first round of the study began on September 12, about two weeks after the freshmen arrived on campus for orientation. The Admissions Office placed the memo in the freshmen’s boxes by lunch time. At 4:30 I received a call from a student who was unable to complete the survey on his computer. It turned out that there is a bug in Microsoft Internet Explorer 4.5 which prevented the survey from working. This is one of the major problems of attempting sociological research using the web. It is very difficult to allow for all possible configurations of browsers and platforms, or to determine where technical difficulties have affected responses. These kinds of problems were recurrent throughout the study. At several points in time, the College-operated server on which the survey resided experienced technical problems which prevented people from accessing it. (This did result in one humorous response in which a student who had been unable to connect contacted me and mentioned the possibility that really I was conducting a study to see how many people would call to tell me that it didn’t work! – he must have been taking a social psychology class.)
 |
 |
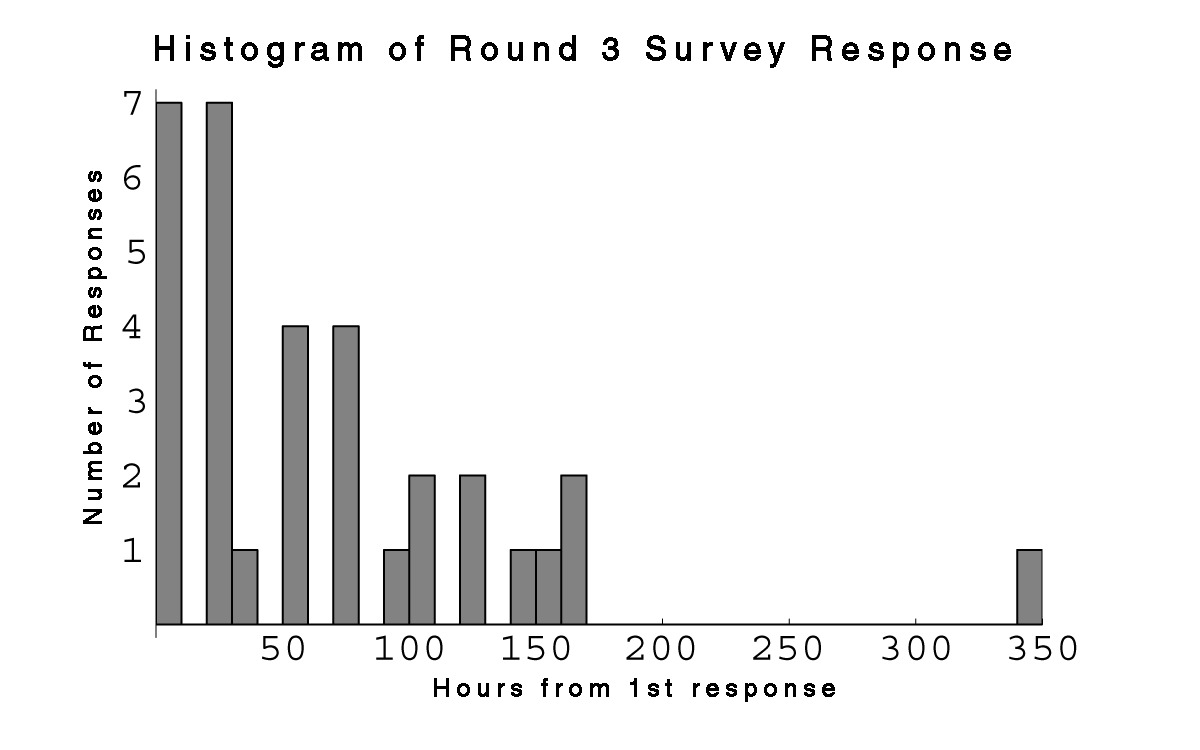 |
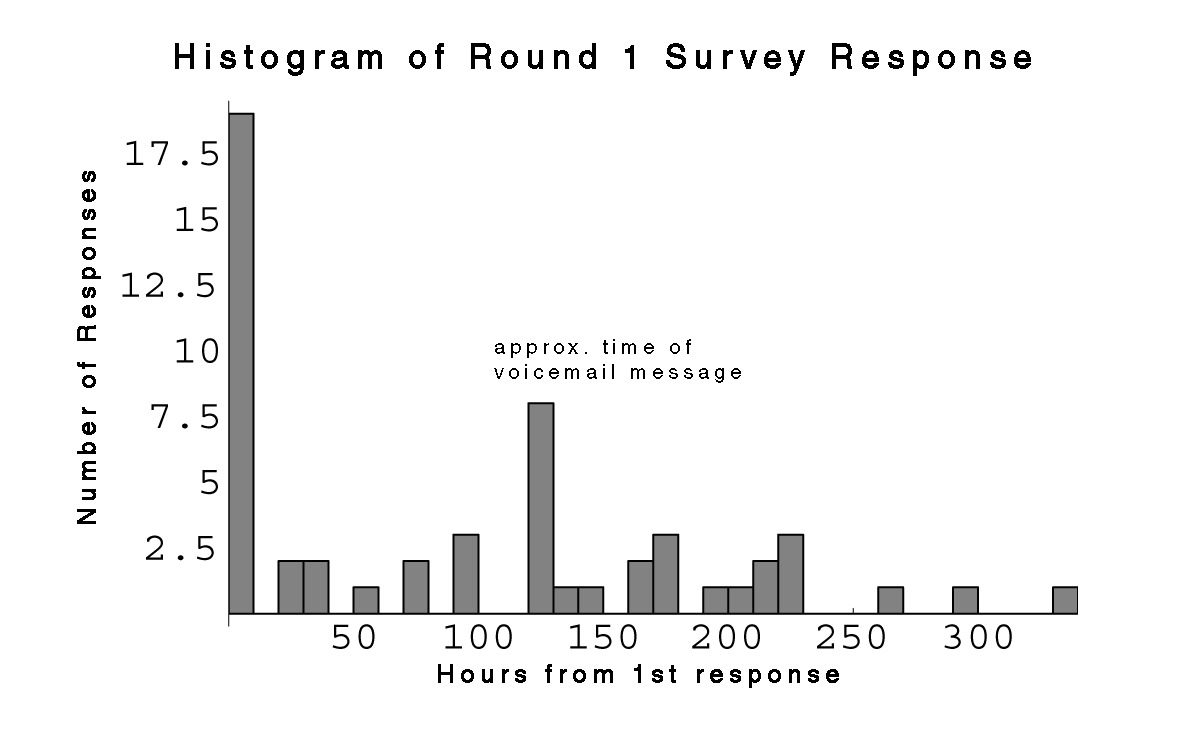
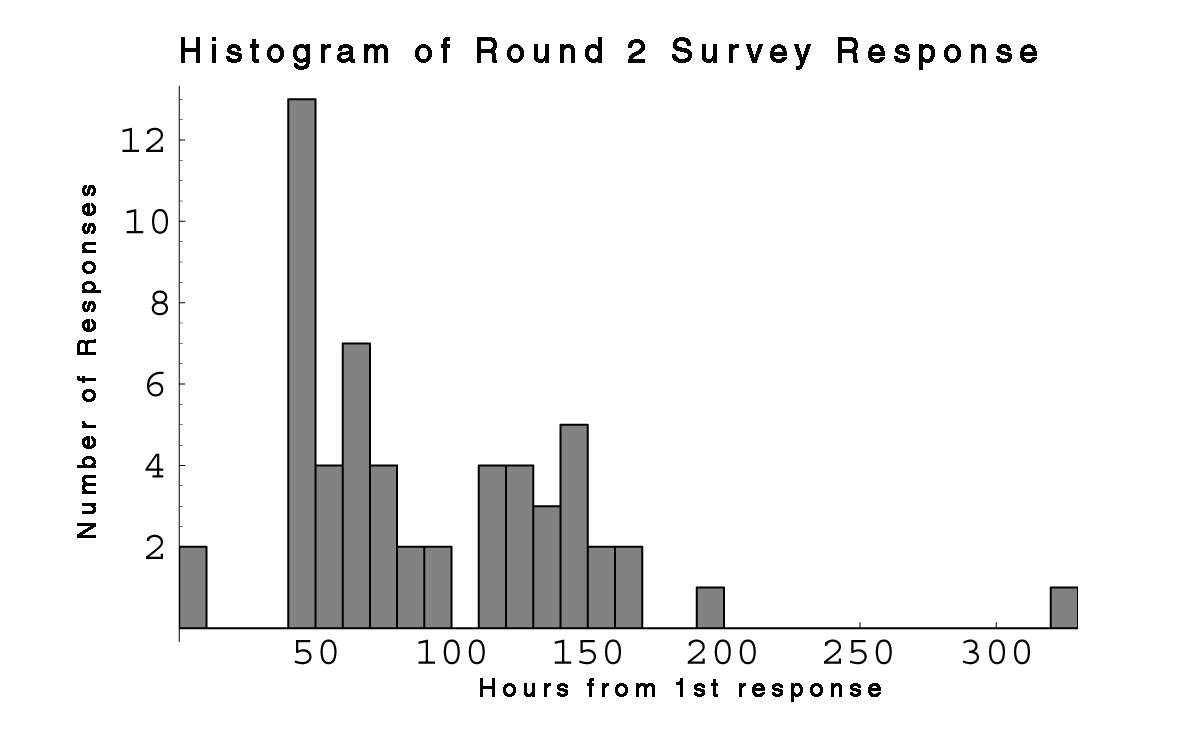
| Fig. 18 Histograms show the patterns of survey responses for each of the three survey waves. The second peak in the first graph corresponds to the time block immediately following the telephone request. |
One week after the initial notification I had received ~30 responses. At 5 p.m. on September 17, I sent a voice mail message to all the first-years who had not responded. The message re-informed them of the study, provided them with the web address, and stressed the personal favor aspect of completing the survey. As Fig. 18 shows, this resulted in an immediate jump in responses. It is interesting that throughout the study, response to the survey was characterized by this kind of near-immediate reaction to the “stimulus” of the request, followed by a long gradually decreasing tail. It is important to remember that the networks generated by the three “rounds” of this study are aggregates formed by a fairly arbitrary collapse of the temporal data. Some of the outlying points of Round I are actually much closer in time to the start of Round II. In a sense, these data shouldn’t really be considered as a “snapshot” of the network at all. The data which I collected using this methodology should be thought of as a collection of self-reported subjective ego networks with specific locations in time. But most types of analysis will require some sort of segmentation into a collective network.
Responses to the first set of questions were based on name recognition. This might be considered a slightly more objective task then rating interaction frequencies, but it is certainly subject to error and bias. One problem which was frequently pointed out by respondents is that Bennington is a community where last names are rarely used, and this is especially true early in the acquaintanceship process. As one respondent put it:
I personally have a problem with when filling out this survey is that I know almost nobody’s last name. For instance, the name Jennifer. I know a few Jens, but not their last name, so I just don’t click yes by these people. The people whose names there is only one of such as [unusualName] are different because it doesn’t matter what their last name is, there’s only one [unusualName].
I was aware that this might be a problem before the survey started. However, it seems likely that in ordinary situations the longer or “more deeply” two people know each other, the more likely it is they will know each other’s last names. The exception to this would be various types of “celebrity” effects, where people’s names might be well known outside of their actual acquaintance networks. There may also be effects of name “memorability” – some names, or some people, may be more unusual or striking, and therefore easier to remember. The questions about conversational frequency are somewhat problematic as well. Respondents may have difficulty accurately recalling people with whom they had interacted.
One potential solution would be to ask a more specific question: “Who did you have conversation with today.” However, to get a picture of more long term contacts, the survey would have to be repeated multiple times. Furthermore, the network survey literature suggests that even when asked questions about specific instances, people tend to respond with their “typical” interactants (Ferligoj & Hlebec, 1999, Marsden, 1990, ) The definition of “conversation” in the prompting question is somewhat ambiguous as well. I was reluctant to use a more specific definition of interaction because it might make the evaluative task more difficult, or potentially exclude some relations. For me, the definition of conversation would include very brief interactions but probably not passing greetings. It is likely that some respondents interpreted “conversation” in different ways, and their interpretation may change as they take the survey. I do not see any way to control for these kinds of effects for self report data. The only solution is to assume that the interpretations will deviate randomly, and to hope that there is no systematic bias in the responses.
Response to the survey was not overwhelming. The first wave contains 53 freshmen – roughly 32% of the class. The second wave has 55 names, and the third has only 32. A total of 76 people took the survey, but I only have complete data (all three waves and target information) for 22 people. One minor complication is that ~6 freshmen whose names were not on the target list responded, so I have no information on indegree (incoming connections) for them.
An immediate question which arises is how representative of the actual Bennington population these data are. Twenty-three percent of respondents indicated that they were male. Although this sex ratio might seem unusual, it is fairly close to the ratio on campus. Nearly all Bennington students live in on-campus dorms or “houses” of 25-30 people, each of which has specific designation concerning issues like smoking and quiet hours, as well as a what is frequently referred to as a “personality.” Residents from all of the 15 houses responded to the survey, but some houses appear to be over-represented. This is more of a problem in the set of 22 respondents who completed all three surveys, as many of the houses drop out completely. It is unclear how this might affect the results of various analyses.
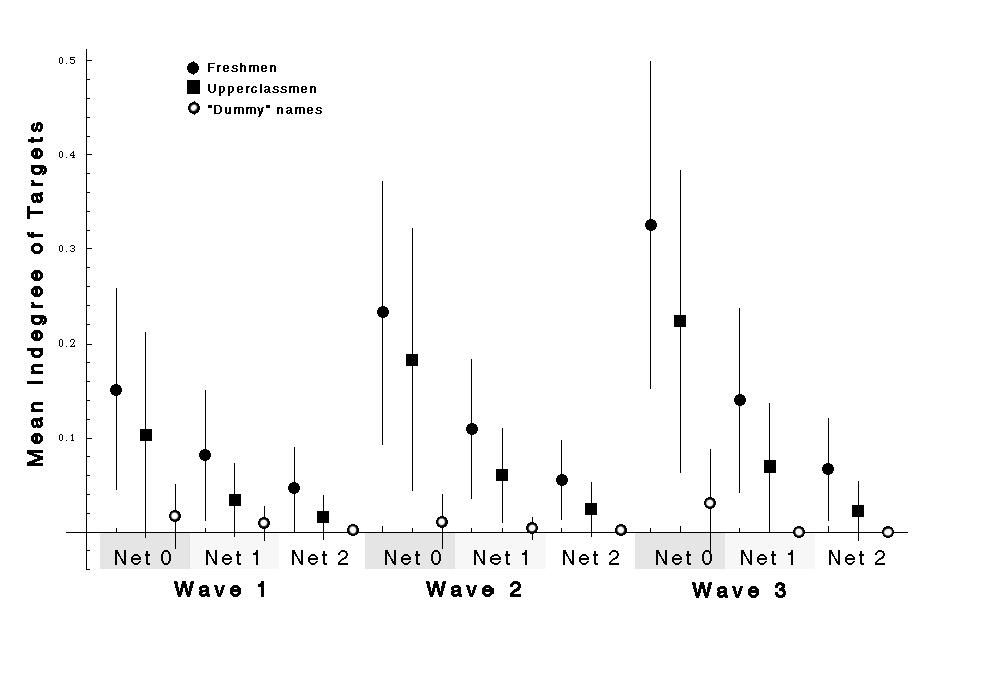
It is also important to consider whether the respondents were treating the survey seriously or were simply clicking through the survey and selecting names at random. The 10 “dummy” names in the survey act as a useful control. The mean indegree score for the name recognition of the dummies (mean number of respondents who indicated that they recognized dummy names) can be compared to the indegree scores for the rest of the “genuine” target names. If the mean for the dummies is significantly lower, perhaps approaching zero, this would indicate that the respondents are at least “separating out” the dummies, and would suggest that they may be attempting to evaluate the rest of the names as well. As Figure 19 shows, this appears to be the case. In all three networks of all waves, the indegree of the dummies is very close to zero and significantly different (two-tailed t-test, p < 0.001) from the other classes. Furthermore, not one of the 76 respondents ever indicated an “at least daily” conversation with one of the dummy names.
 |
|
| Fig. 19 Plot shows the mean indegree for different target categories. Lines indicate one standard deviation. According to a two-tailed t-test, the freshmen and dummy means are significantly different at the p < 0.0001 level. Upperclass and dummy means are significantly different (p < 0.0001), except for nets 1 and 2 in wave 1. For Net 1 and 2, freshmen and upperclass means are different at (p < 0.001), Net 0 is not significant for wave 2. | |
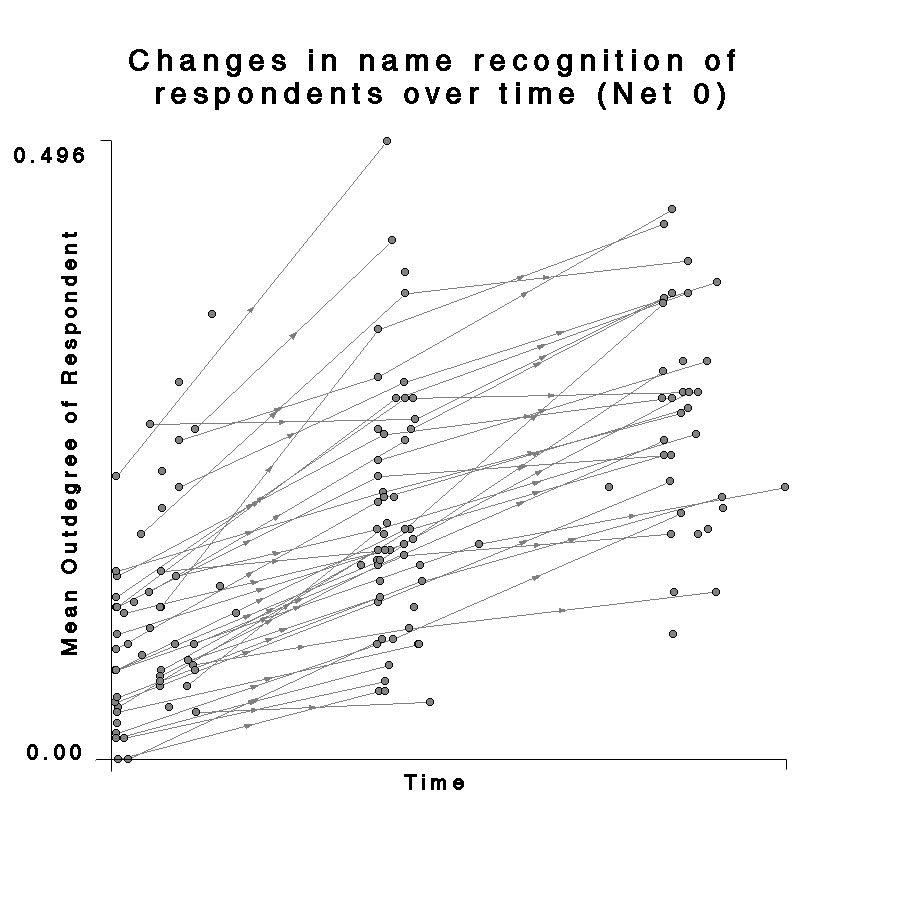
| Fig. 20 Plot of mean Net 0 outdegree for each respondent by rescaled date of survey completion for all three waves. Line is best fit function from regression analysis. | 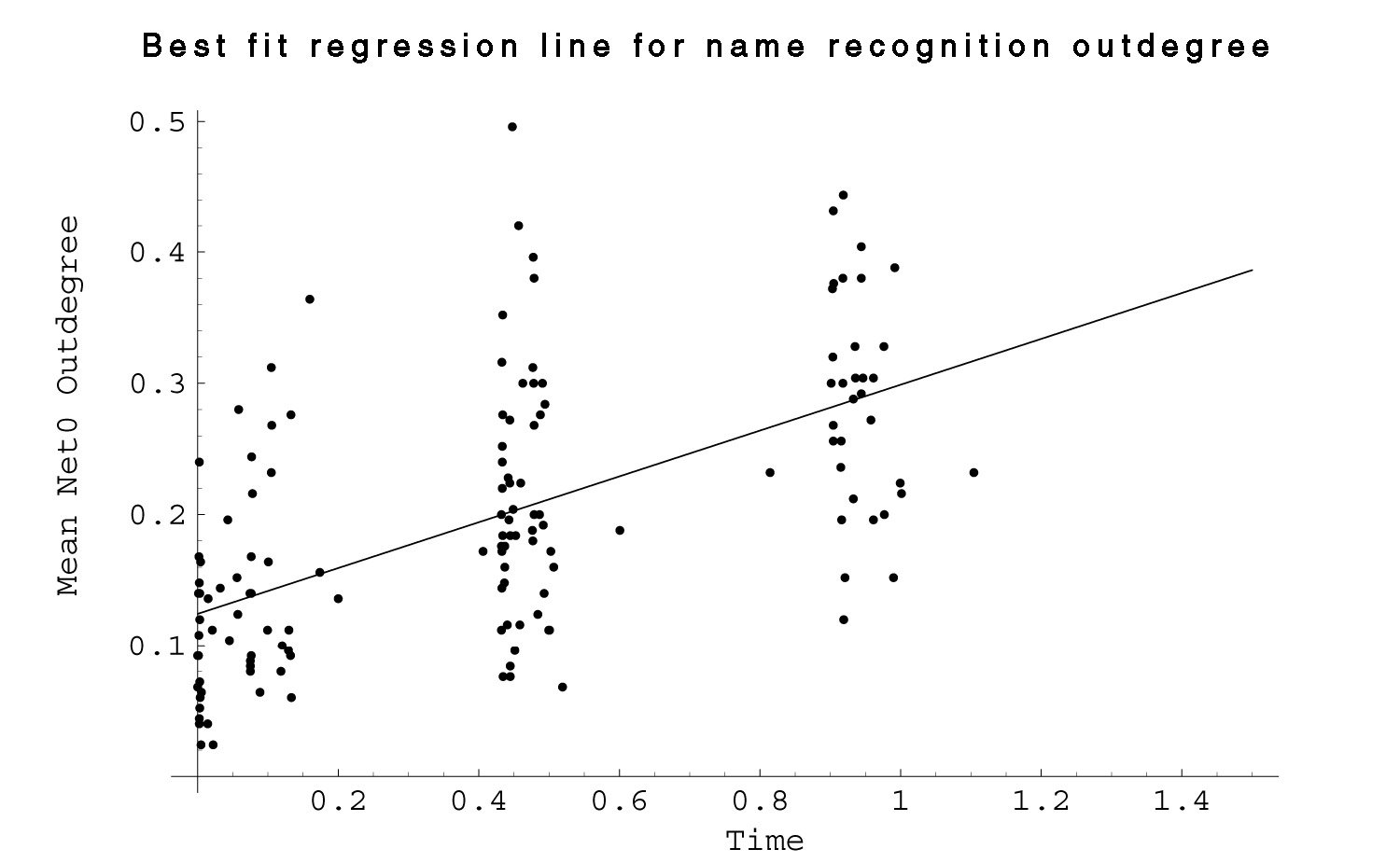 |
As Figures 20-22 demonstrate, the distribution of outdegrees is quite large, and there is a fair degree of “clumpiness” in the temporal data because the bulk of the respondents completed the survey within the first couple of days of each wave. Even so, there appears to be a strong and highly significant increase with time. The line of best fit is approximately 0.12 +0.17 t, with an R-squared of 0.34 and significance (probability of obtaining as good a fit with a random distribution of points) of < 0.001. Although it would be quite difficult to extrapolate out of the sample to estimate a rate curve for the freshmen acquaintance process, it is worthwhile to note that an extrapolation of the curve back in time would give an outdegree value greater than zero before the freshmen arrived on campus. This could mean that students are already familiar with some names when they arrive, (from campus visits, literature, etc.) and/or that the rate of name acquisition changes with time. It seems likely that rates of name acquisition would in fact change noticeably over the course of the term and over a student’s educational career. For one, the size of the community would act as a limiting upper threshold, although that would change every fall as a new class is admitted.
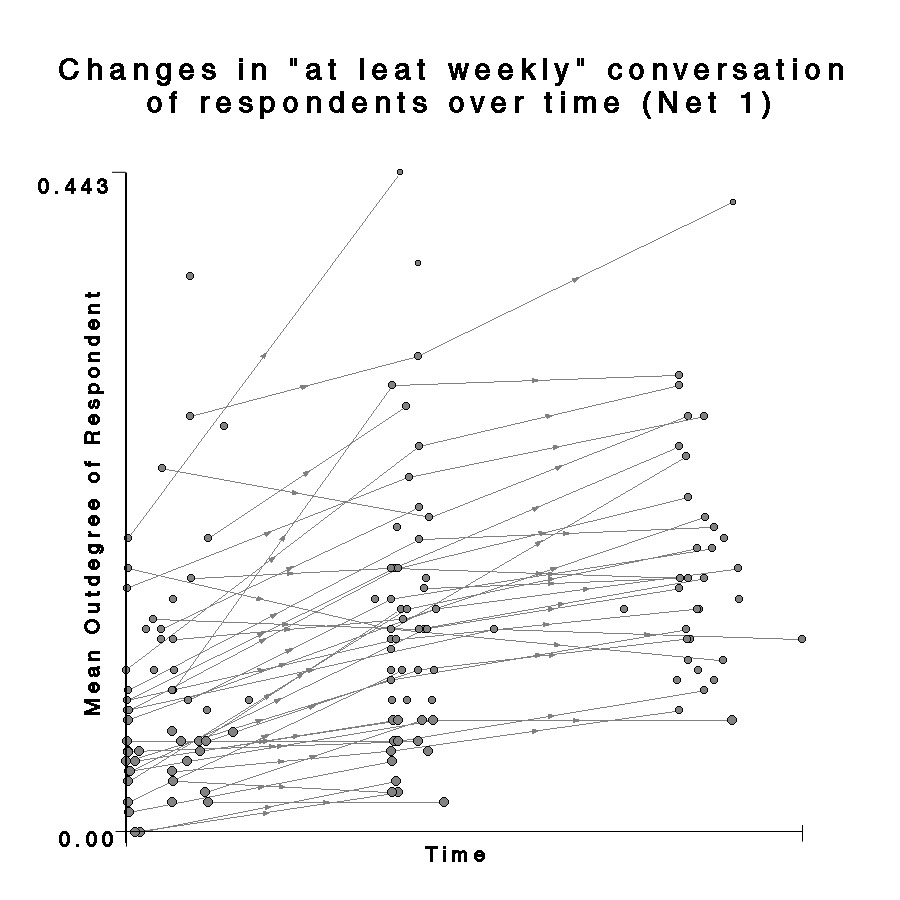
| Fig. 21 Plot of mean Net 1 outdegree for each respondent by rescaled date of survey completion for all three waves. Line is best fit function from regression analysis. | 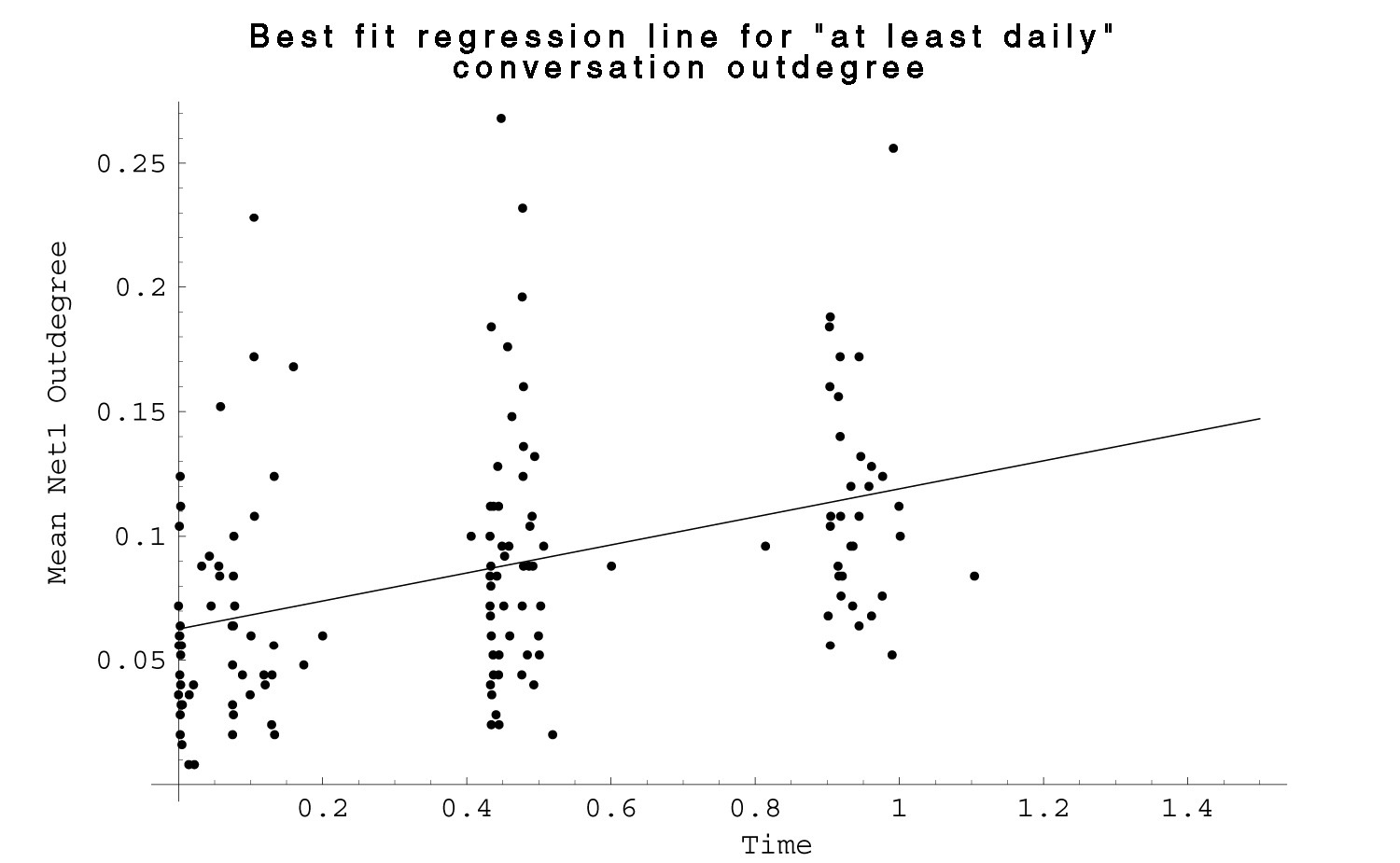 |
| Fig. 22 Plot of mean Net 2 outdegree for each respondent by rescaled date of survey completion for all three waves. Line is best fit function from regression analysis. | 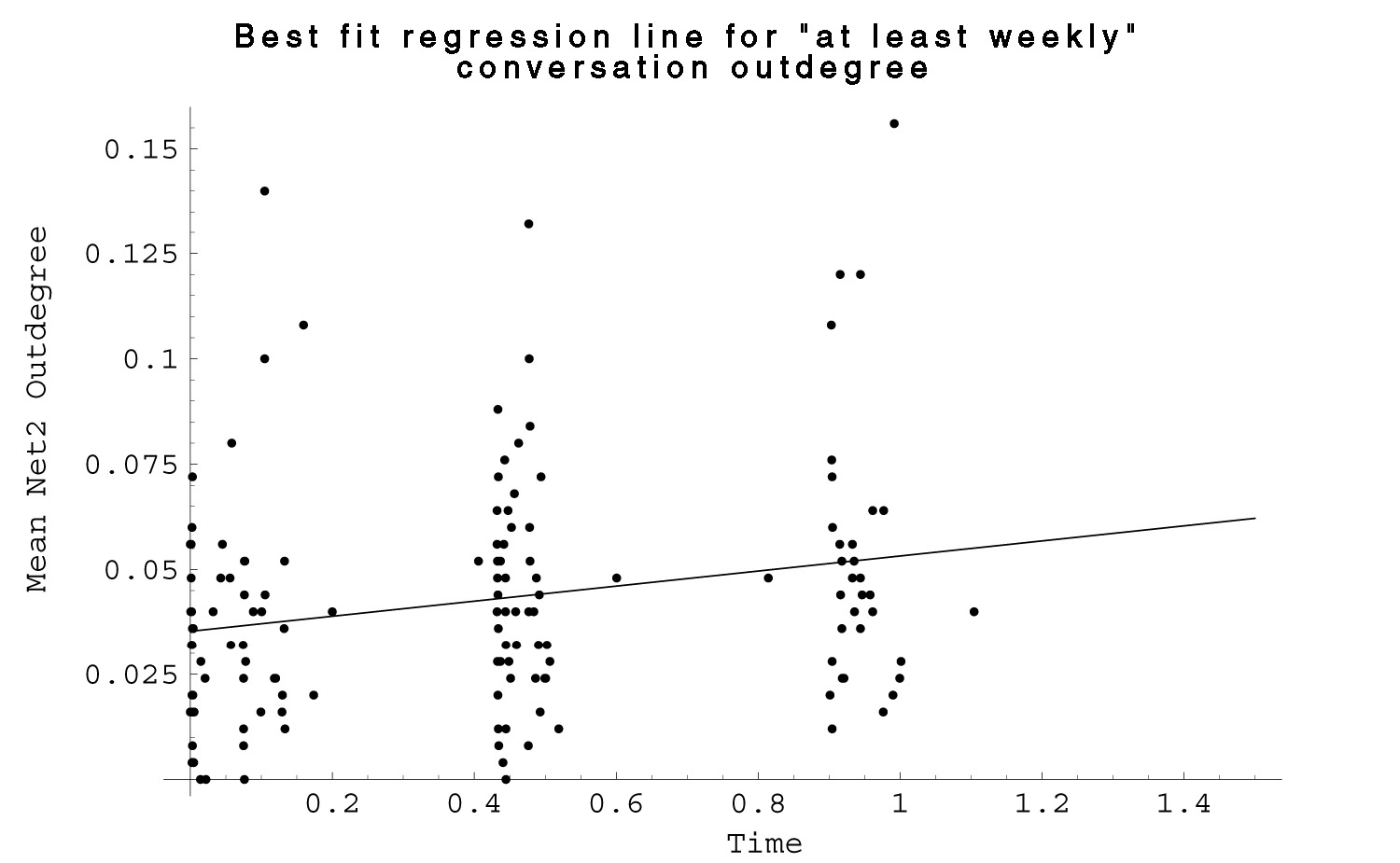 |
I did similar regressions for the daily and weekly conversation outdegrees. (figures 21 and 22.) For weekly conversation, the fit was still significant with an R-squared of 0.15 and p < 0.001, but both the magnitude and slope of the best fit line are much less than was the case for name recognition.
| Fig. 23 Comparison of slopes of best fit regression lines for the three network information categories | 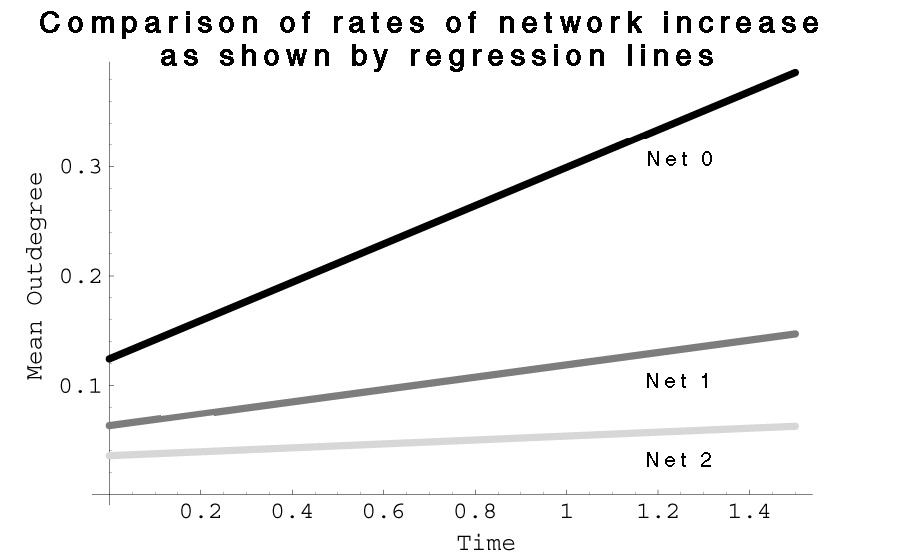 |
The results for daily conversation are much smaller again, and the fit had an R-squared of 0.05 significant at p < 0.01. If the undersampling of the upperclassmen could be ignored and the results taken at face value, relationships between the fitted lines would indicate that freshmen converse weekly with about half the people whose names they recognize, and daily with about one fourth. However, name recognition continues to increase at a much greater rate than the interactional measures. This may be due to time limitation effects – a person can continue learning new names, but presumably they can only converse with a limited number of people in a given day20 – although who the people are may change over time. A similar trend shows up when the data are aggregated into their collection waves and the matrix means (sum of all entries divided by the number) of each network are computed. The means for the matrices give essentially the same data that the regression does, just organized categorically rather then temporally.
| Means (density) of entire network matrices | Wave 1 (N of Obs 13500) |
Wave 2 ( N of Obs 13750) |
Wave 3 (N of Obs 8250) |
|||
| Mean | SD | Mean | SD | Mean | SD | |
| Net 0 | 0.132 | 0.338 | 0.211 | 0.408 | 0.286 | 0.452 |
| Net 1 | 0.065 | 0.246 | 0.091 | 0.288 | 0.114 | 0.318 |
| Net 2 | 0.036 | 0.187 | 0.044 | 0.206 | 0.051 | 0.221 |
Table 1 Density scores and standard deviations for complete (all targets are included) raw network matrices
 |
 |
| Fig. 24 Plots of mean outdegree of respondent by survey completion data. Connected lines indicate the location of the same individual in successive waves. (Vertical scales on the plots are not the same) | 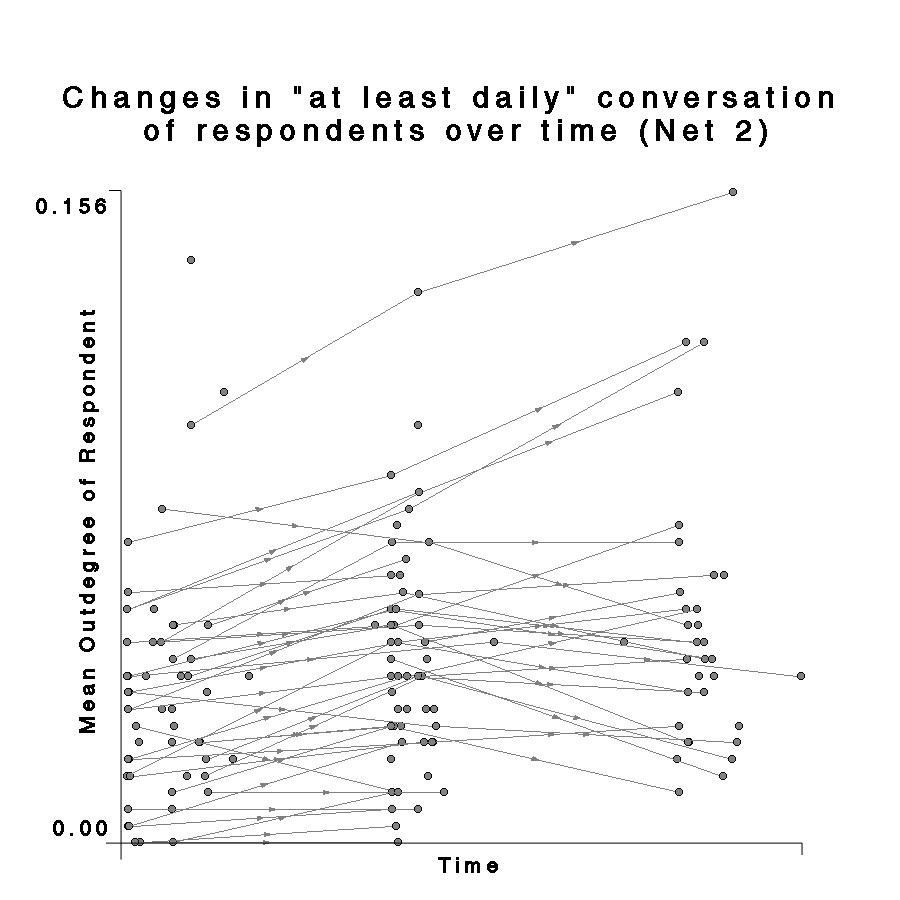 |
One question which is not well addressed by the regression plots is the relationship between the mean outdegree of the group and the trends for individuals. Are the outdegrees of all the individuals in the network changing systematically, or is the change due mostly to a few outliers? Figure 24 again shows plots of time of response against outdegree for every respondent. However, in these plots, individuals who appear in sequential waves are connected by directed lines. This makes the general trend appear even stronger, and also demonstrates a change of rates between the two time blocks. It is also clear that many individuals drop out in the third wave. Examination of the same kind of graph for Net 1 shows some interesting properties which were not apparent in the regression. Again, the overall number of connections in Net 1 is much smaller than in Net 0, but it is also clear that individuals are changing at different rates, and for most of them the increase between the 2nd and 3rd waves is negligible. Net 2 is even more striking. The “at least daily” conversation outdegree of many individuals actually decreases between the 2nd and 3rd waves. This, again, might be an effect of settling – perhaps after the initial flurry of meeting new people, students began to interact with smaller groups of friends.
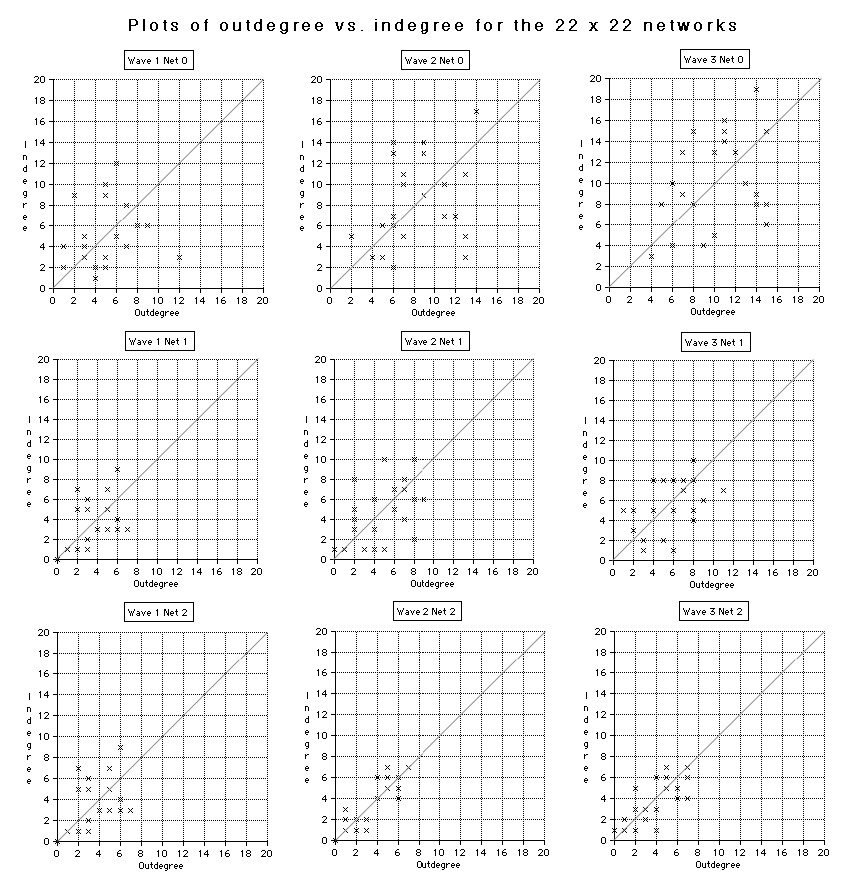 |
| Fig. 25 Plots show the relationship between (raw) indegree and outdegree for the 22 respondents who completed all three surveys. Individuals who’s in- and outdegrees are the same would appear along the diagonal. |
It seems worthwhile to examine the relationship between the in and outdegrees for each individual. Figure 25 shows the indegree and outdegree values for individuals in the 22 x 22 matrices plotted against each other. In this kind of representation, people who have identical in- and outdegrees would appear along the diagonal. (The values for the in- and outdegrees used in this plot are the scores within the matrix, not the scores for the entire target list.) There do not seem to be any systematic trends other than those already mentioned. However, it is interesting that even for the graphs for daily interaction, where a fair amount of agreement might be expected, there is still a noticeable discrepancy between in and out degrees. (Note that these graphs do not directly plot reciprocity because the identities of the in and out degrees are not taken into consideration.) There also may be a slight bi-modality, a segmentation into a high in- and outdegree group and a low group. This trend is also visible in Net 2 in Figure 24, but may simply be an artifact of the small 22 person sample.
The indegrees for all of the 250 targets considered together show the same trends as the outdegrees for all the respondents. To some extent they must do so because, they are extracted from the same matrix, but plotting the indegrees allows inspection of the trends for individuals as well. Figures 26, 27, and 28 show the same kind of information as Figure 24 – changes for each individual from one wave to the next – but in this case the number of individuals remains constant so the information can be presented as lagged plots. For each individual target, the mean indegree value for one wave is plotted on the horizontal axis and its value in the next wave is plotted on the vertical axis. As in the previous plots, individuals who show no change would appear on the diagonal. Although there are 250 points in each relation, many of the points in the plots for Net 1 and Net 2 overlap due to finite size effects. In all cases there are some individuals whose indegree decreases (plotted below the diagonal), but the majority increase (plotted above the diagonal). The largest outlier in the name recognition plot is actually me, as respondents probably had to see my name a large number of times during the survey process.
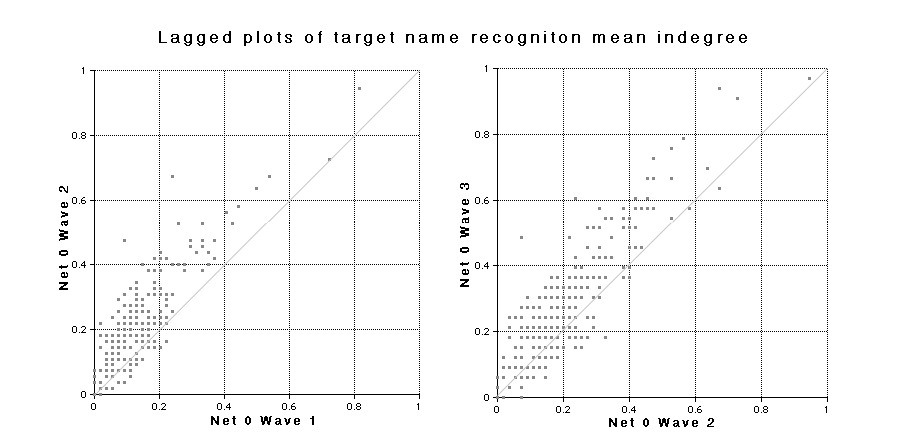 |
| Fig. 26 Lagged plots show the relationship between indegrees in successive Waves for the 250 targets. |
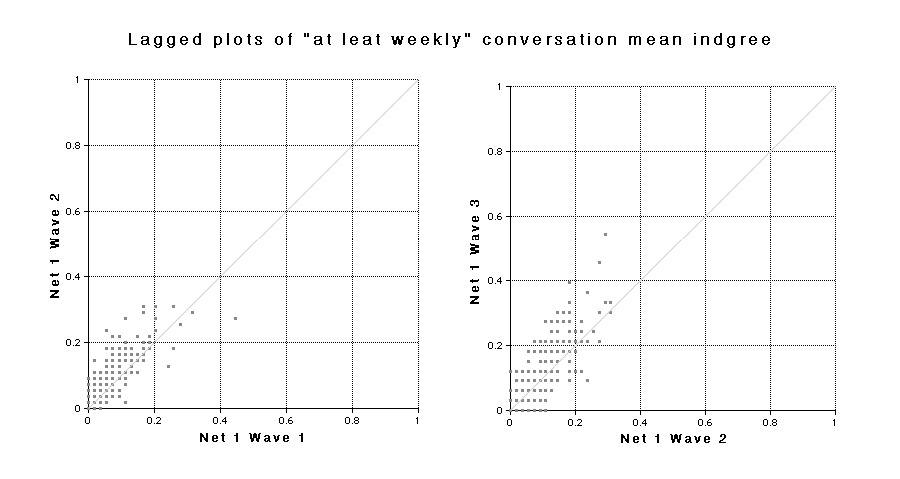 |
| Fig. 27 Lagged plots show the relationship between indegrees in successive Waves for the 250 targets. |
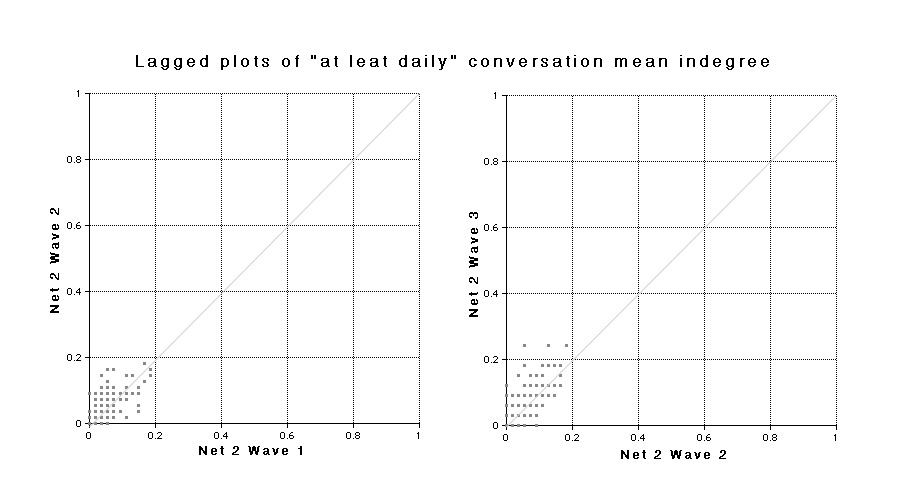 |
| Fig. 28 Lagged plots show the relationship between indegrees in successive Waves for the 250 targets. |
It is important to remember that the indegrees for both upper- and underclassmen are plotted together in these graphs, and that all of the values are from the perspective of the small group of freshmen respondents. There are, in fact, quite significant differences in the aggregate means of these categories. Figure 19 shows that throughout the study, the freshmen targets on average received greater numbers of recognitions and relations than the sample of upperclass targets did. Although this is not terribly surprising, as it seems consistent with my experience that the freshmen associate more with each other than with the upperclassmen, it does provide some evidence that, at least until the end of the term in which the study was carried out, there was a consistent degree of separation, or lack of integration, between the incoming freshmen and the upperclassmen. It would have been fascinating to repeat the survey at the end of the freshmen year to see if the segregation persists, or if the student body becomes more uniformly mixed.
If the network data collected in this study do in some way describe changes in social structure over time, it is likely that there will be correlations between the networks at subsequent times. The interval between the survey waves is small enough that the pattern of connections in one network matrix should be fairly predictive of the connections in the same matrix at the next point in time. In a sense, this is what the lagged plots show, except that they only compare the number of connections and not their actual pattern. The network analysis package UCINET (Borgatti, Everett, & Freemen, 1999) which I used for most of the analysis has a QAP Correlation procedure which I used to estimate the relationships between the networks. According to the UCINET documentation, QAP correlation first computes several standard measures of the correlation between the two (square) matrices, and then computes an estimate of the significance of the correlation by permuting the elements of the matrix a large number of times and counting the number of correlations which are larger or smaller.
I have some doubts about the appropriateness of the standard QAP procedure. Some of the assumptions which must be made about the network lead to overestimates of significance, but at the moment there is no real alternative. Because of the requirement that the matrices be square, I used the 22 x 22 matrices of individuals who responded to all three waves, meaning that the patterns of connections to upperclassmen are not considered in this analysis, and that these results may not be typical of the overall sample. All significance estimates were made with 25000 permutations of the matrices, none of which resulted in correlations as large as the observed correlations, leading UCINET to give significance values of 0.000 for all correlations. This should be interpreted, with reservations, to mean that the following correlations are significant at the p < 0.001 level.
| Net 0 | Wave 1 to Wave 2 |
Wave 2 to Wave 3 |
| Pearson Correlation: | 0.56 | 0.718 |
| Simple Matching: | 0.795 | 0.855 |
| Jaccard Coefficient: | 0.49 | 0.706 |
| Goodman-Kruskal Gamma: | 0.922 | 0.965 |
| Net 1 | ||
| Pearson Correlation: | 0.629 | 0.836 |
| Simple Matching: | 0.882 | 0.94 |
| Jaccard Coefficient: | 0.521 | 0.773 |
| Goodman-Kruskal Gamma: | 0.951 | 0.991 |
| Net 2 | ||
| Pearson Correlation: | 0.665 | 0.86 |
| Simple Matching: | 0.913 | 0.963 |
| Jaccard Coefficient: | 0.558 | 0.788 |
| Goodman-Kruskal Gamma: | 0.958 | 0.994 |
Table 2 QAP matrix correlations from UCINET
Most of the correlation values are fairly large, indicating that the configuration of the network at one point in time is fairly dependent on its previous configuration – an outcome which would be unlikely if respondents were clicking through the survey at random. Although the different correlation measures emphasize different aspects of the relationships, the trends are consistent: the correlations increase from Net 0 to Net 1 to Net 2, and from the first time period to the second. This makes some sense when considered in light of the rate findings from the regression. Individuals are added to the interaction networks much more slowly than to the name recognition network, so the changes are less and the correlations should be higher. Table 3 presents a summary of the element-wise changes in the 22 x 22 matrixes from wave to wave.
| Net 0 | Wave 1 to Wave 2 | fraction of matrix | Wave 2 to Wave 3 | fraction of matrix |
| 0 -> 0 | 290 | 62.8% | 245 | 53% |
| 0 -> 1 | 86 | 18.6% | 56 | 12.1% |
| 1 -> 0 | 11 | 2.4% | 13 | 2.8% |
| 1 -> 1 | 75 | 16.2% | 148 | 32% |
| Hamming Distance | 97 | 69 | ||
| Net 1 | ||||
| 0 -> 0 | 363 | 78.6% | 354 | 76.6% |
| 0 -> 1 | 44 | 9.5% | 22 | 4.8% |
| 1 -> 0 | 13 | 2.8% | 7 | 1.5% |
| 1 -> 1 | 42 | 9.1% | 79 | 17.1% |
| Hamming Distance | 57 | 29 | ||
| Net 2 | ||||
| 0 -> 0 | 387 | 83.3% | 397 | 85.9% |
| 0 -> 1 | 22 | 4.8% | 10 | 2.2% |
| 1 -> 0 | 20 | 4.3% | 7 | 1.5% |
| 1 -> 1 | 33 | 7.1% | 48 | 10.4% |
| Hamming Distance | 42 | 17 | ||
Table 3 Changes in matrix elements (ignoring diagonal)
Surprisingly, there are quite a few names “forgotten” between the waves. Almost 13% of the names present in wave 1 are not present in wave 2. Although I expected some change in both directions in the conversation networks, the magnitude of name loss is unexpected, possibly indicating a fair amount of error in the data collection. It might also indicate increased ability on the part of the respondents to distinguish between the various target names. In other words, a respondent might have chosen more than one Sarah in the first round, but by the 2nd round the last names were familiar and it was possible to distinguish between them. The overall rates of change (Hamming Distance) are also much less in the 2nd time period. This may indicate some degree of “settling” of the network into stable configurations, or ceiling effects due to the limited population size. Again, this is difficult to tease apart for Net 1 and Net 2 because they are strict subsets of Net 0 – any names which are omitted in error from Net 0 must also be missing from 1 and 2 .
One of the main things which is interesting about these data are their evolution over time. But since the dimensionality of the data is so high (connections between a large number of individuals), there are only certain kinds of relationships that can be examined with traditional time-series techniques. One approach is to perform a set of operations on the network data in order to extract some aggregate measure or statistic, and then analyze the trajectory of this parameter over time, as in the network size example above. Another approach, recently developed by Tom Snijders, is to construct models of the entire network as a stochastic dynamical process, and analyze the properties of the models and their fit to the observed data. (Snijders 2001a, Snijders & van Duijn 1997)
One way to think about this is with an analogy to regression analysis. The basic idea in regression analysis is to determine a line or polynomial curve that “fits” the observed data with the least amount of error. In a sense the curve is a model for predicting the relationship between the dependent and independent variables, and the appropriateness of the model is evaluated by calculating some statistic describing the degree of error (un-explained variation) between the model and the observed data – the most commonly used statistic is RMS error.
In SIENA, Snijders’ experimental network dynamics statistics package, the model is an algorithm for generating networks at successive points in time, and the statistics used for comparing the observed and predicted networks are various graph- and network-theoretic statistics: density, number of triads, etc. In traditional regression, the parameters control the relative effects of the polynomial terms of different degrees. In SIENA’s algorithms, the parameters control the relative effects of the formal descriptions of various network processes: transitivity, reciprocity, density effects, etc. Although the specific assumptions of Snijders’ “stochastic actor-oriented models for network evolution” are likely to be crucial in interpreting the results, I’m not going to discuss the details here. The basic idea is that the evolution of a sociomatrix can be modeled as continuous-time Markov chain Monte Carlo process. This is somewhat similar to model I discussed above. Snijders’ perspective is more flexible and perhaps more “realistic” than previous approaches as it does not require dyad independence.
The basic idea for our model for social network evolution is that the actors in the network may evaluate the network structure and try to obtain a ‘pleasant’ (more neutrally stated, ‘positively evaluated’) configuration of relations. The actors base their choices in the network evolution on the present state of the network, without using a memory of earlier states. However, they are assumed to have full knowledge of the present network. … It is immaterial whether this ‘network optimization’ is the actors’ intentional behavior; the only assumption is that the network can be modeled as if each actor strives after such a positively evaluated configuration. (Snijders, 2001a, p. 4)
Although the notion of intentionality (or perhaps the lack of it) may raise a red flag here, the equations of the model are flexible enough that the “intentionality” is really only a weighted tendency for the algorithm to seek certain network configurations -both intentional and non-intentional properties of actors could be represented in this fashion.
SIENA’s method for estimating network parameters is simultaneously elegant and ridiculously brute-force. Because it is generally not possible to derive analytically the various network effects from observed data, a Monte Carlo search of possible model parameters is run. For each parameter setting, a stochastic Markov process is used to generate the network specified by the model, and this network is compared to the observed network. The process is repeated thousands of times until (hopefully) there is convergence on a set of parameters which are capable of generating networks which change over time in ways which are measurably similar to the observed networks. By generating a large number of networks with the same parameter settings, a rough idea of standard deviations and errors can be obtained as well.
There are several things which are problematic about this method. Because it is essentially a stochastic process, there is a limited degree of repeatability. And, just like in any other comparison of models to real data, just because the model fits the data doesn’t mean that it is the best possible or most accurate description of the data. I particularly appreciated the comment in Skog’s paper:
At the risk of stating the obvious, I should stress at the outset that the nature of this dynamic cannot be logically deduced from the data. The deductions go in the opposite direction. From presumed mechanisms once can deduce certain structural features. When present, these empirical facts may be said to support the proposed mechanisms, but since it will always (or nearly always) be possible to find other mechanisms with similar consequences, support is not the same as proof. (Skog, 1986, p. 4)
Also, the process of eliminating unnecessary parameters from the model is a fairly subjective one, and may introduce biases towards expected effects. One advantage of Snijders’s approach is that, unlike the QAP permutation approach, it does not simply use random networks of equivalent density for significance estimation; it generates networks of the same hypothetical model class and makes comparisons with multiple statistics. Another advantage of SIENA is that not only will it estimate the relative effects of various network generative functions, it will also estimate the impact of traits held by the actors (individual covariates), or relations between the actors (dyadic covariates), if the data files are included along with the network matrices. This makes it possible to investigate the role of other structural networks (house membership, etc.) in mediating the formation of the observed networks, or the role of attributes like sex.
To investigate the potential network effects present in the name recognition network (Net 0), I fed in the 22 x 22 networks for each of the three waves, starting the analysis with several parameters and eliminating those which were least significant, as suggested in Snijders’ documentation (Snijders, 2001b). Throughout the analysis, the model generally exhibited very good convergence, such that when the deviations of observed parameters during the run are compared to the goal parameter, the “t”-statistics are very close to 0. Most parameter estimates are based on around 1400 iterations. The rate parameter estimates are based on 500 iterations, and describe the number of changes per actor estimated to have occurred between the observations, including canceling changes. The other parameters indicate the weights for the objective functions of their respective network effects. After the estimates of parameter significance were complete for each Net, I repeated the analysis from scratch, including a house affiliation dyadic covariate matrix (discussed below) The models still showed excellent convergence, and similar significance. Tables 4 through 6 show the estimates and significance of the parameters arrived at for the name recognition network, the “at least weekly” conversation network, and the “at least daily” conversation network. A “t”-test value greater than 2 indicates significance at the 95% confidence level. In some runs, non- significant effects were included for comparison, although this is likely to reduce the significance of other effects.
| SIENA estimates for Net 0 | Estimated Parameter | Standard Error | “t”-test |
| Rate parameter period 1 | 5.5197 | 0.5698 | 9.687 |
| Rate parameter period 2 | 3.5731 | 0.4633 | 7.712 |
| density (out-degree) | -0.7272 | 0.3081 | -2.361 |
| reciprocity | 0.6819 | 0.1913 | 3.565 |
| popularity of alter | 2.4919 | 0.4332 | 5.752 |
| houseAffil (centered) | 0.3269 | 0.2156 | 1.516 |
Table 4 Results of SIENA parameter estimation for 22 x 22 name recognition matrices
| SIENA estimates for Net 1 | Estimated Parameter | Standard Error | “t”-test |
| Rate parameter period 1 | 3.6631 | 0.5691 | 6.437 |
| Rate parameter period 2 | 1.6297 | 0.3291 | 4.952 |
| density (out-degree) | -0.8045 | 0.4720 | -1.704 |
| reciprocity | 1.7217 | 0.3455 | 4.983 |
| balance | 3.1383 | 0.9773 | 3.211 |
| popularity of alter | 1.3921 | 0.9083 | 1.533 |
| houseAffil (centered) | 0.4781 | 0.2912 | 1.642 |
Table 5 Results of SIENA parameter estimation for 22 x 22 “at least weekly” conversation matrices
| SIENA estimates for Net 2 | Estimated Parameter | Standard Error | “t”-test |
| Rate parameter period 1 | 3.076 | 0.6363 | 4.834 |
| Rate parameter period 2 | 1.0578 | 0.3173 | 3.334 |
| density (out-degree) | -2.3114 | 0.2772 | -8.338 |
| reciprocity | 3.1006 | 0.4736 | 6.547 |
| houseAffil (centered) | 1.0565 | 0.3859 | 2.738 |
Table 6. Results of SIENA parameter estimation for 22 x 22 “at least daily” conversation matrices
Although it is difficult to summarize the trends in the various effects due to the somewhat haphazard nature of the analysis, there appear to be several which are significant. The most consistent result is that the rate parameters of the two time blocks differ; the estimation shows 2 to 3 times more activity between waves 1 and 2 than between waves 2 and 3. There is also a large reciprocity effect at all of the network levels, but both the weight parameter and significance are greatest in the daily conversational interaction network. Reciprocity indicates mutual selection: if i chooses j, j is likely to choose i. It makes sense that the effect would be the strongest in the daily interaction network, because repeated daily conversations generally require mutuality, where name recognition can be one-way if there is a “celebrity effect”. In fact, there appears to be a popularity effect which is strong and significant for name recognition, but not for the other two networks. This suggests that there are some individuals in this freshmen sample whose names are recognized regardless of their network location. There is a negative density effect which is strongest and most significant in Net 2, and this is consistent with the results of the outdegree plots for the whole data set. This might indicate some sort of “cap” on daily conversations – individuals with high outdegrees are unlikely to add more connections. There were several other effects that were significant in one or two rounds (balance, transitivity), but as these estimates are only for the 22 x 22 matrices, the samples size is probably too small for them to be reliable. I also attempted to use the individual covariate feature to investigate the possible effects of sex on interactions, but the results were neither significant nor consistent. All of these findings should be checked by repeating the analysis with a larger sample of the data set – this would be possible because SIENA allows some missing values in the matrices – and by using the simulation mode of the software to investigate the distributions in more depth.
In an earlier section of the paper I suggested that a useful way of visualizing the effects of social structure on interaction was as a collection of networks describing the parameters which might promote or discourage interaction to some degree. The idea is that observed interaction is a result of the sum of the various effects. At Bennington, house membership could potentially be a strong predictor of interaction. It has certainly been my experience that members of the same house tend to hang out together. One reason might be that because the housing office attempts to maintain the “personalities” of the houses, the individuals placed in a house are similar in some respects and would be likely to interact anyway. In later semesters people have the option of changing houses to be with their friends. But for the freshmen, it seems that house co-membership could be considered as a kind of structural embeddedness, both social and physical, which may foster increased interaction among residents. The results from the SIENA analysis seem to indicate that this is the case, at least for the daily conversation network. Because the respondents indicated their residence in the demographic portion of the survey, it was possible to transform the information into a respondent x respondent affiliation matrix with ties between the actors that share a house. This matrix was then given to SIENA as a dyadic covariate file to be included as a parameter for estimation.
| Simple Matching | Wave 1 | Wave 2 | Wave 3 | |||
| corr. value | p-value | corr. value | p-value | corr. value | p-value | |
| Net 0 | 0.753 | 0.142 | 0.643 | 0.062 | 0.576 | 0.062 |
| Net 1 | 0.803 | 0.113 | 0.779 | 0.01 | 0.751 | 0.016 |
| Net 2 | 0.807 | 0.104 | 0.842 | 0.004 | 0.827 | 0.006 |
Table 7 Estimates of correlation between the house affiliation matrix and the other 22 x 22 matrices
As a check on the slightly “black box” SIENA methodology, I also used UCINET’s QAP correlation procedure to directly estimate the ability of the house affiliation network to predict tie formation. Table 7 shows that there are fairly strong and significant correlations between the house affiliation network and the daily conversation network for wave 2 and wave 3. This seems to agree with the SIENA results, suggesting that house membership may not be important for name recognition, but it does affect who people interact with on a daily basis later on in the term. Again, I would have much more confidence in these results if the 22 respondent sample was considerably larger and less skewed in house membership.
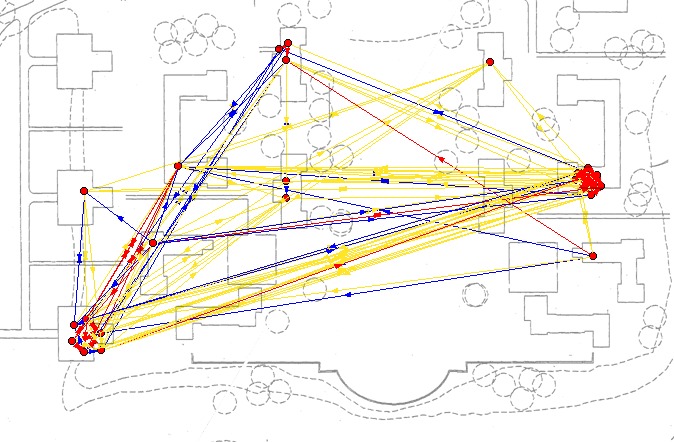
Figures 29 – 31 show the 22 individuals who were present in all three survey waves plotted by their residence against a map of the physical layout of the college. In these networks, the ties from Net 0, Net 1 and Net 2 are aggregated on the same graph and indicated by color coding. This layout makes it quite clear that the sample of 22 is not very representative of the College, at least as far as housing is concerned. It is not possible to determine whether the large number of ties relating the two houses with the most respondents is due to a large degree of social interaction between the houses or, more likely, due to the high connectedness of subsets property of random graphs. In these images it is also difficult to see what is happening with the in-house ties.
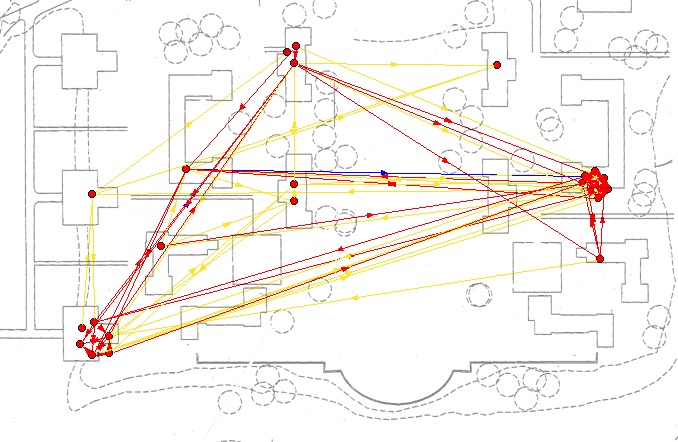 |
| Fig. 29 Spatial representation of the Wave 1 connections in the 22 network superimposed on a map of the Bennington campus. Nodes are position according to the geographical coordinates of their residence. |
 |
| Fig. 30 Spatial representation of the Wave 2 connections in the 22 network superimposed on a map of the Bennington campus. Nodes are position according to the geographical coordinates of their residence. |
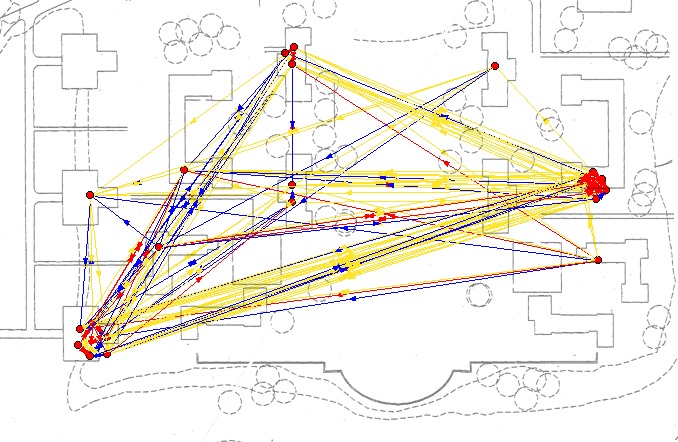 |
| Fig. 31 Spatial representation of the Wave 3 connections in the 22 network superimposed on a map of the Bennington campus. Nodes are position according to the geographical coordinates of their residence. |
To correct for this, it is possible to display the networks using a spatial layout which is based solely on the pattern of ties rather then the physical location of the respondents. A commonly used method is Multidimensional Scaling – which attempts to optimize the locations of the nodes so that the Cartesian distances between them corresponded well to a parameter like graph theoretic distance. However, MDS requires symmetric data as input, which would mean discarding a great deal of detail from an already sparse data set.
Another common technique is to use one of a number of “spring embedding” algorithms to position the nodes. Spring embedding techniques generally treat the edges between the nodes as springs of a given weight, and iteratively adjust the locations of the points until a “minimum energy” configuration is found. The problem is that many of the routines are stochastic, poorly understood, and there may be multiple local minima at which the layout can get stuck, meaning that the results can be highly dependent on the given starting positions for the nodes. The layouts for Figures 32-34 were constructed using the Kameda-Kawai algorithm in the recently developed free network analysis software PAJEK (Batagelj & Mrvar 2001). All of the figures were constructed with the same initial configuration of the 22 nodes arranged around a circle in sequential order. This means that although they may not be the clearest or absolute “lowest energy” representation, they are repeatable and comparable to each other.
These graphs convey qualitatively many of the features detected in the SIENA analysis: (1) the graphs for the name recognition network become increasingly connected and dense with time; (2) the conversation networks seem to show some degree of segmentation, especially in the 2nd wave of Net 2; and (3) the individuals in the segments correspond quite strongly to the house groups in the spatial layout. The subset nature of the networks is quite clear as well; the Net 2 networks appear to function as a core or “backbone” for the Net 1 networks. It is also interesting that the differentiation between the classes of networks seems to increase with time. Net 0, Net 1 and Net 2 in wave 1 are qualitatively quite similar, as opposed to the strong contrast between Net 0 and Net 2 in wave 3.
The patterns of connections evident in these graphs can be somewhat misleading, as the only connections shown are those between the individuals in the 22 underclassmen sub-sample. In other words, nodes which appear isolated in these graphs may be quite highly connected, but their ties are to individuals who are outside of the sample or didn’t respond to the study. Figures 35-37 show bi-partite graphs of the “at least daily” out-connections for each of the 22 respondents in the sub-sample. Each of the white nodes (open circles) corresponds to one of the 250 target names in the survey, and the shaded nodes denote the respondents. For clarity, all of the targets with no incoming ties were removed. The graph is slightly confusing because the 22 respondents are displayed in two locations, both as a respondent and as a target, and the connections between the respondents are not directly shown. The advantage is that it better illustrates the presence of many two-step ties and connections to individuals not included in the sample. The graphs also demonstrate how complicated these representations can become. I have not included the graphs for name recognition or for the complete set of respondents because they become so dense that they are almost illegible unless displayed in an animated 3D format.
| Fig. 32 | 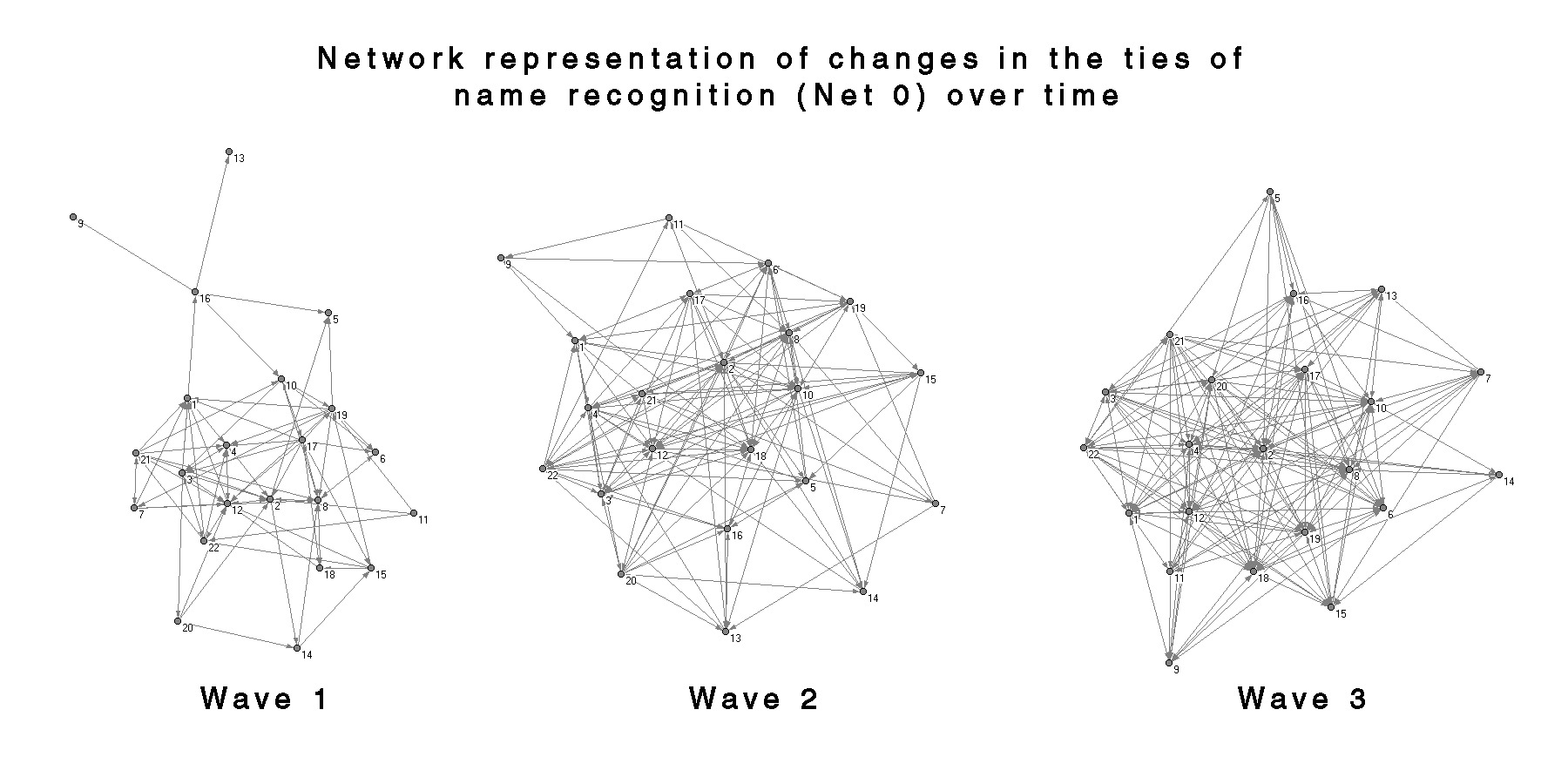 |
| Fig. 33 | 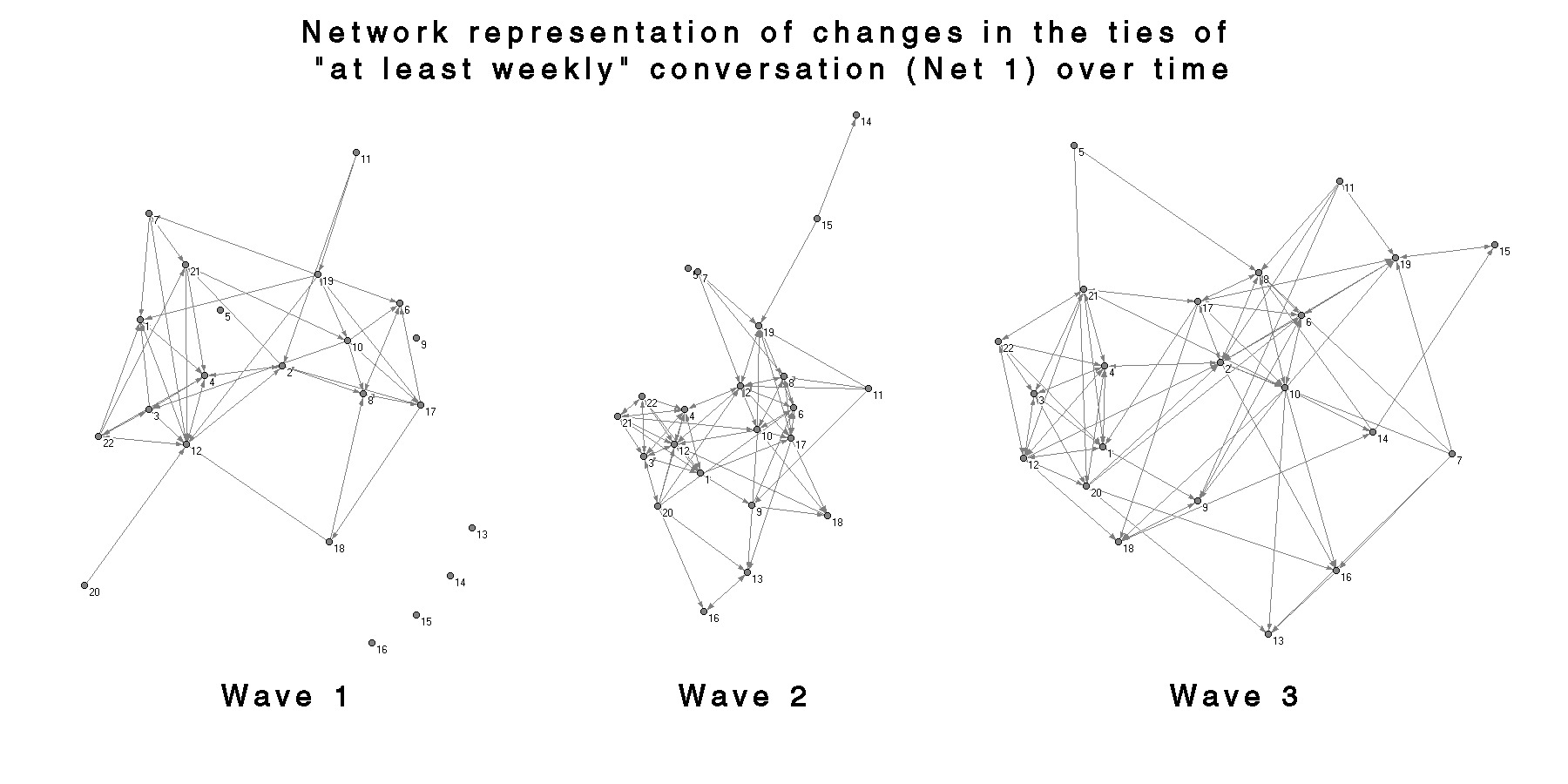 |
| Fig. 34 | 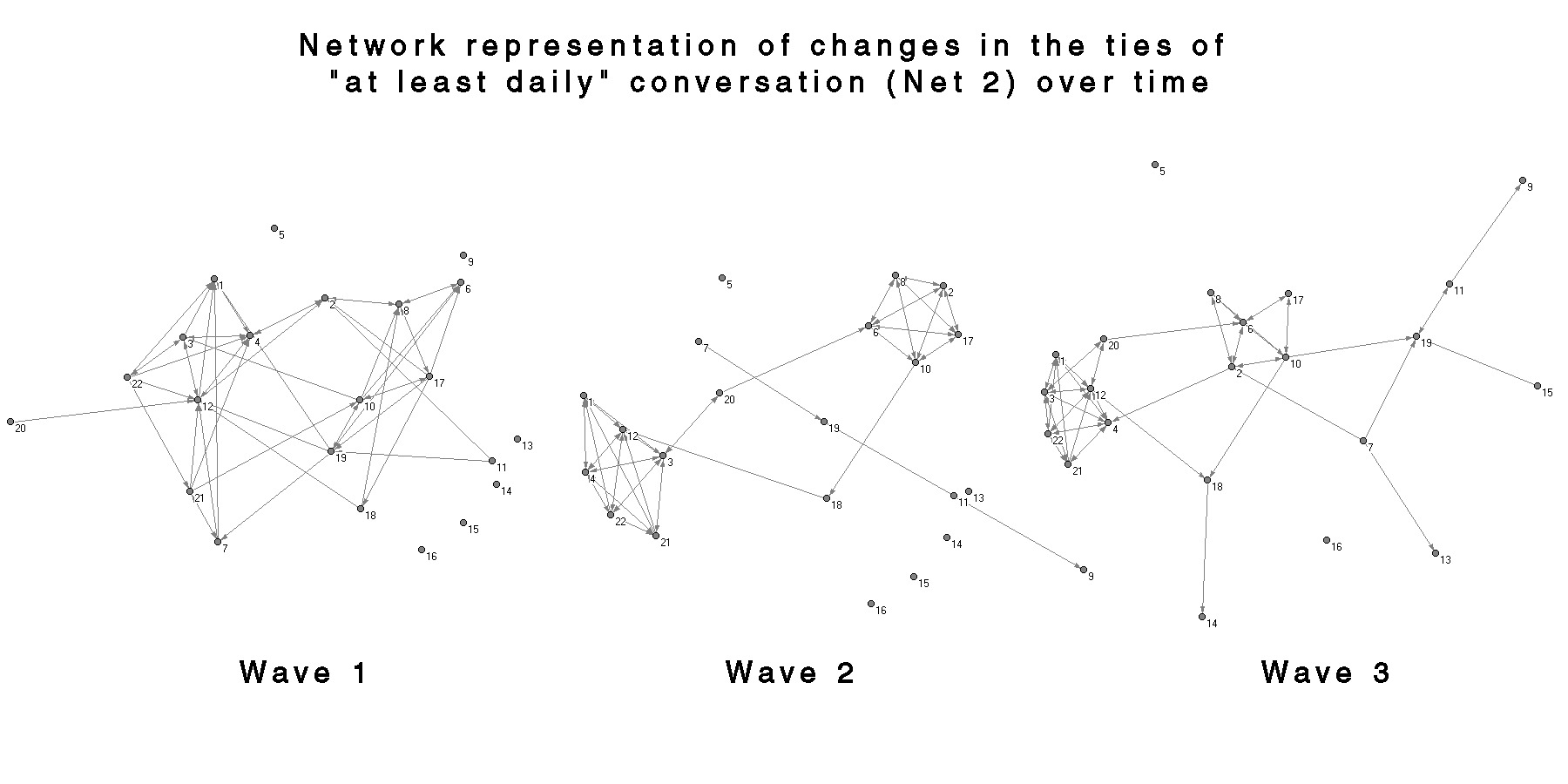 |
| [This figure was not included in the original thesis. It is a “movie” constructed by interpolating the coordinates of the three “frames” (Kamada-Kawai layouts) of the “at least daily” (net 2) conversation network. The idea is that the motion allows the eye to make visual comparisons of the nodes’ relative locations. The interpolation was done using the PajekAnimator applet.] |  |
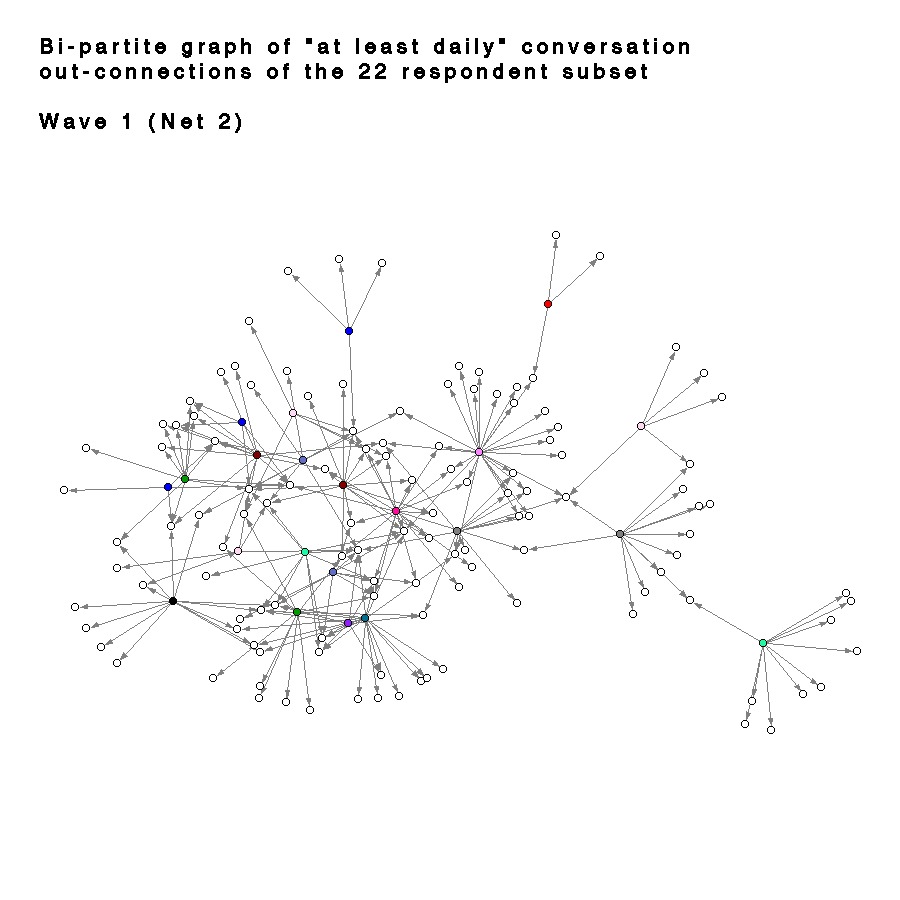 |
| Fig. 35 Spring embbedd layout of the Bi-partite graph connecting the 22 respondent subset to the 250 target names. |
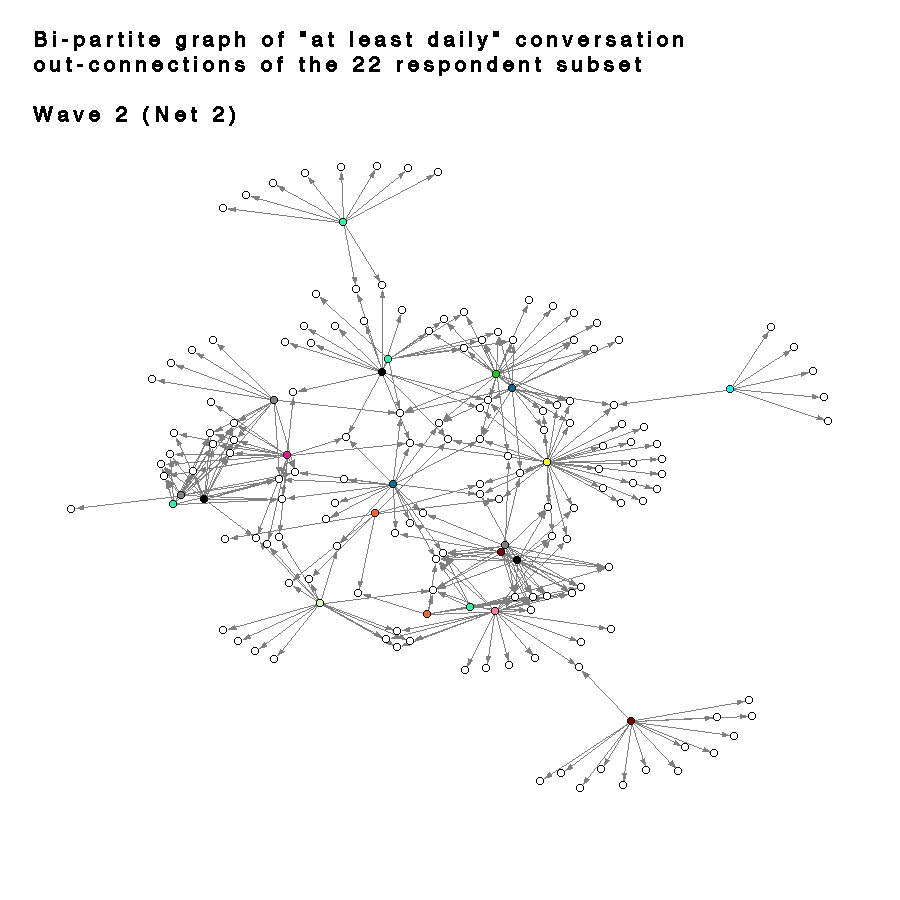 |
| Fig. 36 Spring embbedd layout of the Bi-partite graph connecting the 22 respondent subset to the 250 target names. |
 |
| Fig. 37 Spring embbedd layout of the Bi-partite graph connecting the 22 respondent subset to the 250 target names. |
Implications of the study results
A crucial question is how the data I have collected can be used to support or contradict the assumptions I’ve been making about models of social group formation or information and cultural transmission. In a sense, by testing the relative importance of various effects on the formation and dynamics of social networks, I’m already assuming one of the things I’d like to demonstrate: that information flow is closely related to communication networks. What I have not done is directly examine the dynamics of information and culture. However, I believe that the data I have presented provide fairly convincing evidence both for the existence of growth and change in the social environment studied, and for the feasibility of using this kind of survey instrument for obtaining meaningful data. I have complete network data on fewer than 30 individuals, so statistical resolution is less than overwhelming, yet I believe it is still possible to reject two crucial null hypotheses. The first null hypothesis is that the methodology is inappropriate and the collected data are spurious, exhibiting no consistent relationship to the actual patterns of social relations among the respondents. The highly significant rejection of the control group (the dummies) by the respondents, the relative consistency of the responses, the presence of detectable structure in the data, the agreement with qualitative impressions, and anecdotal accounts from the participants, all argue convincingly that the participants took the study seriously, answered to the best of their ability, and that the data in some way reflect real world relations – as much as such data can. They second null hypothesis, that there are no observable trends in the data which could not be best accounted for by random error, can also be rejected due to the strongly significant increase in name recognition outdegree over time, and the changing correlations with respect to static matrices.
I believe that the “success” of techniques based on description of network dynamic effects and structural relations in predicting (albeit retrospectively) the observed data provide grounds on which to accept tentatively the feasibility of models which conceptualize the gross dynamics of human relationships withen a social network framework. By that I mean that even if useable predictive models are still out of reach, at least the idea of modeling individual relations as dependent on network structures and variables with a scope larger than the dyad seems to be on the right track. The results also emphasize the importance of considering social relations as inherently time based. There are considerable amounts of change at all levels of the survey data, more than could easily be accounted for by simple survey error. The high degree of changing relations and rates suggest that in many cases, representing a network as a static “snapshot” would mean sacrificing some of the most crucial information.
Can any specific conclusions be made about Bennington from the data? Although the results of various analyses suggest strong effects within the sample, mapping results from that data onto conclusions about the real world is somewhat tricky. My original intention was to come up with estimates for “cliqueishness” and average “social distance” for the campus, or at least the freshmen social network. It is, however, the nature of networks that they do not segment well into useable subsamples. That is, estimates of some properties do not scale well from a sample to a population. For example, if the sample of 22 individuals was truly random, the likelihood of getting multiple individuals who are members of the same close social group would be quite small. (Klovdahl, 1989) So simply scaling up the number of cliques observed in the sample to the population size would probably result in a gross underestimate of connectivity. More advanced extrapolation techniques could be used, but they would necessarily entail some strong assumptions about the unobserved properties of the network.
The same problem exists for geodesic distances. There is a good chance that any given distance between two individuals would in fact be considerably shortened by the inclusion of the un-recorded connections to a non-respondent. Some of these data could potentially be extracted from the much larger collection of bi-partite data, but considerable work would need to be devoted to coming up with an appropriate methodology. I was quite surprised to discover during the analysis that there is no real procedure for estimating the correlations between non-square matrices. As I mentioned earlier, this necessitated the exclusion of a great many data on connections to non-respondents and upperclassmen for many of the analyses. So the few tentative conclusions I have made are really more about general properties of network formation, as observed at Bennington, rather than about properties of Bennington’s networks.
However, the results do have some interesting implications. It seems that by the end of their first term at Bennington, the freshmen recognize the names of roughly a third of the freshmen and a quarter of the upperclassmen. They claim to converse at least daily with less than 5% of the campus. There appear to be a few people whose names are known by nearly everyone, but the vast majority are recognized by a much small fraction. Respondents learned names at a relatively high rate, but this rate appears to decrease with time. There is some evidence of less then perfect mixing between the freshmen and the upperclasses. Who people talk to on a daily basis appears to be somewhat determined by what house they live in, and some individuals seem to be consistently tardy in filling out sociological surveys!
Even though I have devoted a great deal of space in earlier sections to a discussion of information and culture transmission, this study was not designed to examine transmission directly. Mostly this was due to the difficulty in conceving of an appropriate methodology, but also because, as I mentioned before, if the assumption is made that transmission requires communicative contact, an examination of contact may provide an upper bound for transmission. My original intent was to conduct an additional study of actual transmission, for which the social network data would provide a necessary baseline for comparison. However, it is important to realize that there is a fair amount of culture or information transmission implicit in the network data I have collected. Knowledge of the names of the members of the Bennington college community can be viewed as a property of the students’ local subculture. But, like many cultural traits, name recognition is neither simple nor arbitrary, because knowing people’s names has direct utilitarian function. The data in this study show that people recognize the names of far more individuals than they actually claim to interact with on a weekly basis. Are these extra names infrequently encountered acquaintances, or names that have become familiar “second hand” through conversational interactions with others? Are names learned directly from an introduction, perhaps catalyzed by an existing relationship, or by conversational transmission?
A way to clarify the conceptual distinction is to consider the Bennington name recognition ability of the parents of a Bennington student. If their child keeps in touch at all (perhaps an unlikely assumption!), the parents might become “enculturated” with the names of the student’s close friends and instructors, despite the fact that they have not been introduced in person. I would argue that this is an example, and a measurable one, of information and cultural transmission. The name recognition data in this study can be conceived of as a combination of cultural knowledge and network information. Unfortunately, this complicates the issue and does not provide a clear means of separating out the variables. However, a separation may not be necessary, if the questionable choice is made to assume what we are trying to establish: Independent of whether the names are learned through direct interaction and introduction or second-hand through gossip, in most cases the knowledge is still mediated by conversational contact. That is, it might be expected that individuals would be more likely to learn the names of people who are at short acquaintance-chain distances from them in the Bennington network than the names of those who are further away. This hypothesis could be tested directly by examining correlations between the appearance of new names and the distances on the conversational networks. Unfortunately, this would again require a much more complete data set or the ability to estimate correlations between non square matrices. And a positive result still wouldn’t establish whether cultural or informational items which are not as closely tied to interaction as name recognition would still be transmitted along the lines of social ties.
Another potentially strong predictor of network ties which I have yet to examine is academic course enrollment. Bennington college is characterized by relatively small class sizes and most courses provide frequent opportunities for discussion, interaction, and the establishment of acquaintanceships or friendships. Most of the respondents completed the course-listing portion in the demographic section of the survey. These data can eventually be recoded and analyzed in the same manner as the house affiliations.21 When discussing the house affiliations I mentioned that individuals may have been placed in the same house on the basis of their presumed compatibility, and this may somewhat obscure the structural effects of house membership. There is a related problem with analyzing the structural effects of course enrollment.
Because people usually choose their courses on the basis of interest in the subject, the courses may be encouraging interactions between individuals with similar interests who would have sought each other out anyway. But this again requires the assumption I have been suggesting throughout: that people may preferentially interact with others who are culturally similar to them. If it were possible to establish some sort of “cultural similarity score”, it would be feasible to test for these effects in the data. Although the question of what traits such an index should be based on is closely tied to the unanswered questions of this thesis, an extremely crude analysis could be made on the basis of country or region of origin, or native dialect. Bennington has a substantial international student population, and it is my experience that individuals from the same country tend to associate preferentially with each other. This assumption could be tested in further analyses.
19 I discovered later (I was informed by respondents) that at least two of the names on the list given to me by the Dean’s office contained misspellings. This does present a problem, but both names were distinctive enough that they are unlikely to have been confused with other individuals.
20 At one point during my Junior year, I attempted to log all of my interactions to get a very rough estimate of my own interaction density. The method was crude and I only managed to keep it up for for 2.5 days, but I ended up with an average of around 72 interactions with 40 people per day. However, it is difficult to make a comparison to the network data, as I was not a freshmen at the time and the sample period was so short.
21 In addition, the data could provide a fascenating tie-in to Shazia Rahim’s (2001) research on Bennington’s curriculum structure and faculty interaction networks.