
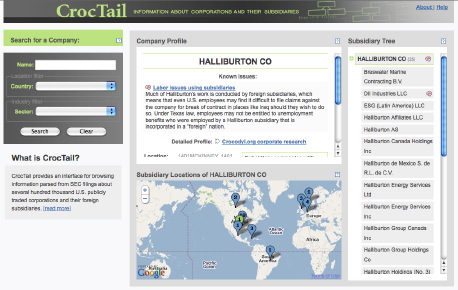
For the past several months, Greg and I have been working on project to scrape corporate subsidiary ownership relations from Securities Exchange Commission filings. The first part of the project launched today! So now you can pull down company names and relationships for more than 200,000 publicly traded U.S. corporations and their subsidiaries from http://api.corpwatch.org. If writing code is not your thing, we also built an interactive browser for the data at http://croctail.corpwatch.org.
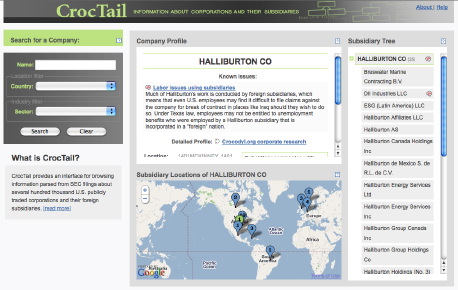
The CrocTail application is closely linked with CorpWatch’s Crocodyl.org corporate research wiki so in addition to displaying the hierarchy, and location for each company, it also allows researchers to tag the subsidiaries with short notes indicating various corporate responsibility issues. Many thanks to Tonya and Lena at CorpWatch for letting us work on this project, and Sunlight Foundation for funding it. They’ve written a press release for the project launch.
To learn a bit more about the scope of the data and what we actually did, check out the project FAQ page.
Some notes about the data
This project was really hard for a number of reasons. First, there is a lot of data, the SEC has records for more than a million companies. Parsing the data from the filings is a serious challenge because the companies don’t provide the data in a standardized format–some are in tables, some in lists, some have indentation to indicate hierarchy, others list percentages of ownership, etc. Greg had to do all sorts of black magic with Perl and regular expressions (and lots of cursing) to get it to work. And there are definitely improvements to be made. If you poke around a bit, you’ll start finding some errors. But the biggest part still to go is completing the time aspect of the API. Since I’ve got kind of thing for dynamic networks, this is the part that I think will be most interesting.
In this first stage, the API is only serving up data from 2008 (the most recent complete year of data) but we’ve parsed up through 2009 and back to 2000. Through a combination of the existing CIK ids on the filing companies, and various name matching tricks, we’ve been able to link up filings over time. So it should be possible to track the progress of mergers and divestment. Limited of course by the fact that companies are apparently pretty good exploiting loopholes to keep sensitive information from 10-K filings, and also that the ownership criteria can seem somewhat vague or arbitrary.
For example, Coca Cola has three corporate hierarchies. If you read the forms, you can tell that they are all controlled by the same company, but technically they are not “owned” by the parent company. Getting the data into the db is one thing, but the hard part is designing the API to have simple quires yet give sensible responses. For example, when a company changes its name, and you search for the old company name, should we return the old name or the new name? We’ve got a plan for how were going to do it, but would love to see any examples of other APIs dealing with time-varying data, especially time varying trees like we have here.
The fact that we do see so many trees (rather than more complex network types) I think may be a bit of an artifact of how the companies report data, in reality, I expect that the actual networks of control and asset flow are much more complicated, especially if we were seeing joint ventures, etc.
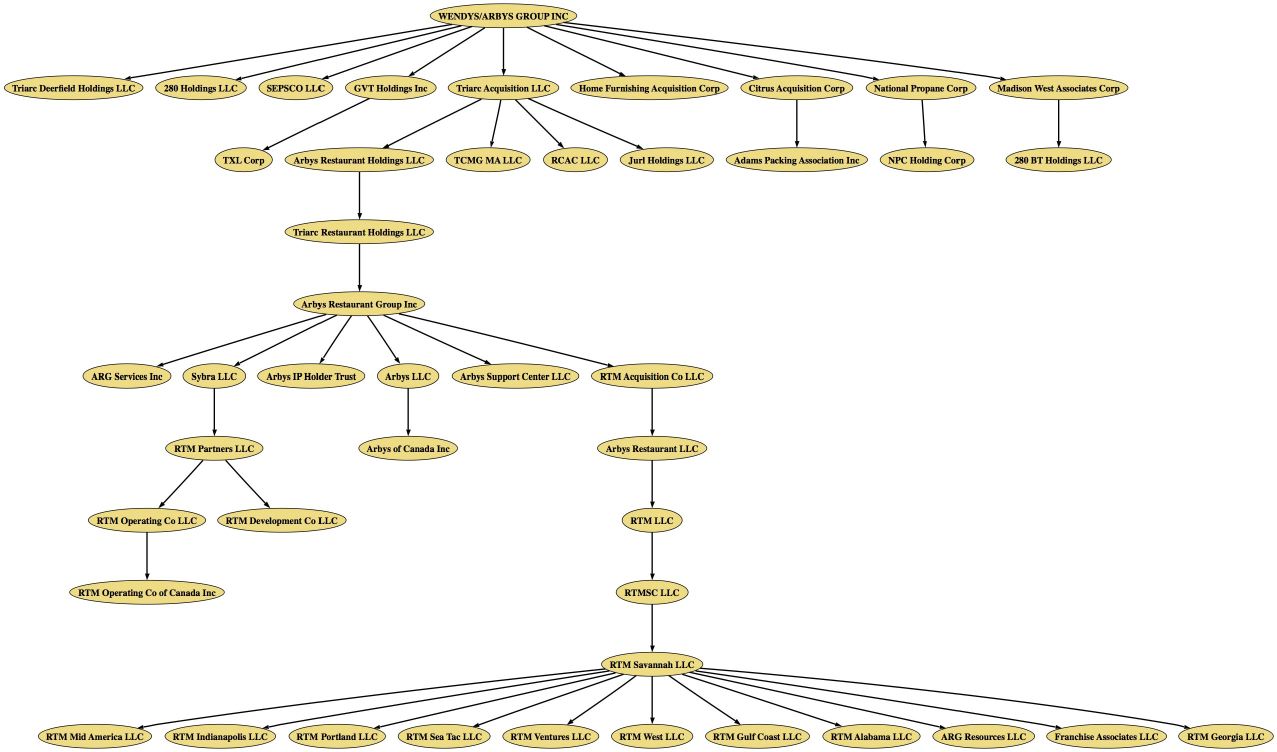
Image above is the corporate hierarchy for Wendy’s / Arby’s Group, extracted from the API and run through GraphViz — just ’cause they have a nice deep hierarchy.
My hope for the project is that, as it expands, we will end up with a very good, very large list of corporate names and aliases with associated ids. All for free, (currently you have to pay thousands of dollars per year for this type of data from commercial provider) and maintained by a community for accuracy. This may seem like something only slightly obsessive data geeks could love, but here’s why it is cool: if lots of researchers and website builders use the same sets of names and ids when they are collecting and tagging their data, all of those data sets should be able to easily match up with each other as well. Whoo hoo! ;-)
Is anyone actively maintaining and/or improving the Corpwatch API?
CorpWatch keeps the servers on, and the scrapers still run regularly to update the data, but there has not been any funding for active development in a long time.