
 Despite the mobility and “small world” social connectivity people living in modern culture, regional difference in culture do seem to persist on both the nation and neighborhood levels. The Soda vs. Pop map may have been created almost as a joke, but seems to reveal very real regional divisions in word uses. Obviously, terms for carbonated drinks may not be tightly correlated with other cultural traits, but it is an intriguing image — and quite a relief after the deluge of red-state blue-state political maps based on voting districts.
Despite the mobility and “small world” social connectivity people living in modern culture, regional difference in culture do seem to persist on both the nation and neighborhood levels. The Soda vs. Pop map may have been created almost as a joke, but seems to reveal very real regional divisions in word uses. Obviously, terms for carbonated drinks may not be tightly correlated with other cultural traits, but it is an intriguing image — and quite a relief after the deluge of red-state blue-state political maps based on voting districts.
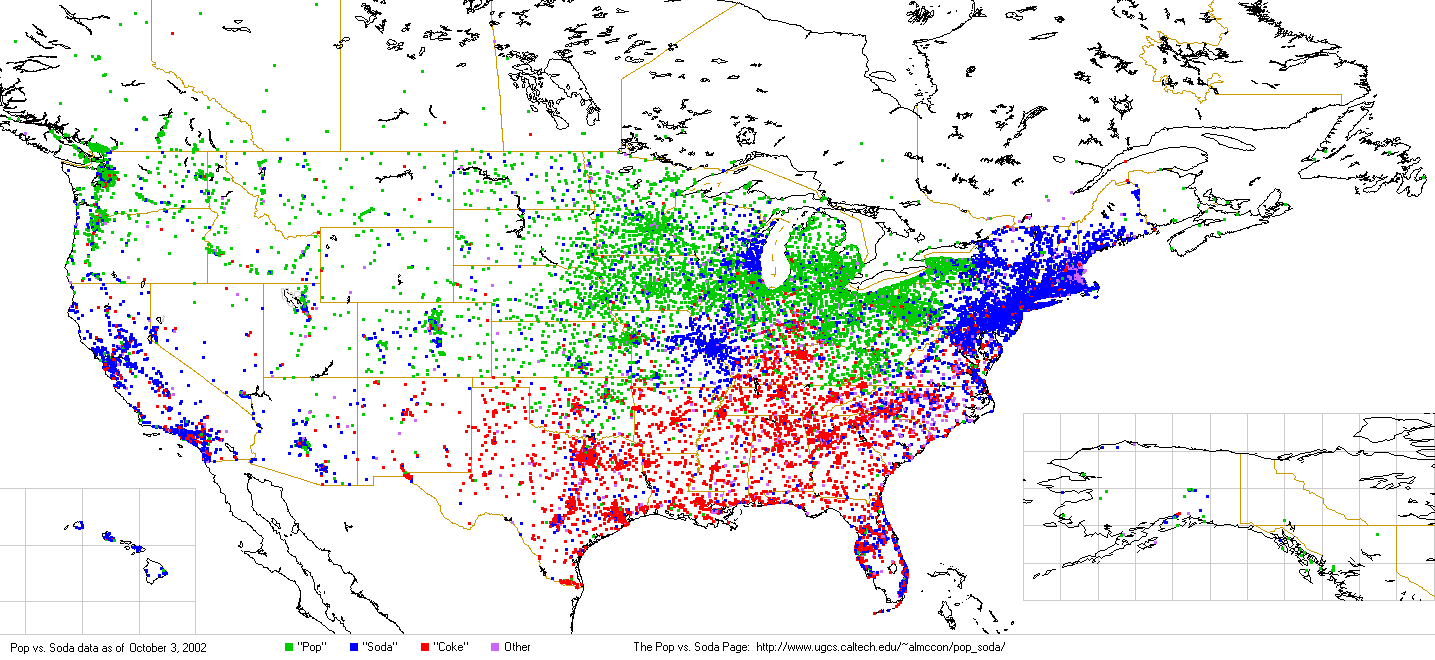
Alan McConchie collected the data by asking visitors to the site to answer the question “What generic word do you use to describe carbonated soft drinks?” So there is definitely some odd internet answers, but the sample size is fairly large, 120,000 people. So why is the St. Louis area so different from its surroundings?
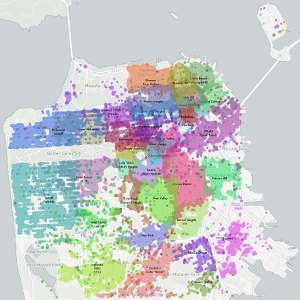
The Neighborhood Project uses combination of scraped craigslist housing posts that include a neighborhood tag and people’s self-reported neighborhood locations in San Francisco. In aggregate, they reveal the boundaries of the neighborhoods — at least as experienced by craigslist users.
Closeup:
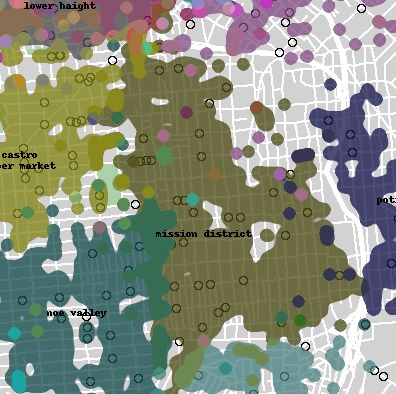
For many of us, neighborhoods are weak affiliations and neighborhood-scale boundaries are more real-estate conveniences than cultural divides. But there are sometimes strong affiliations within cities. The invisible boundaries of various gang territories don’t seem to appear in the map, but they might show up if patterns of movement were more visible.
What defines the boundaries of a neighborhood? Social class and urban history? Ethnicity and language? Are there basins of attraction around certain road arteries or transit hubs? Do people stay mostly within their neighborhoods for certain kinds of trips (like grocery, school, laundry, etc?)
In theory, as everyone these days is carrying around a cellphone with moderately good gps, it should be possible to actually track out where people go, and reveal the neighborhoods that way. Usually only law enforcement and phone companies have that data, but there is a company, SenseNetworks that lets people install an app on their phone and opt in to tracking.
![]()
In theory, they use it for “people who like this cafe also like..” services, but but they also sell the data, a bit spooky. It is not clear how many subscribers they have, or how representative a sample of the city, but it appears they are at least able to generate maps of interaction densities.
UPDATE:
Forgot to mention an earlier post that included some interesting links in tracking people flows, mostly at the room or city level. This image by Thomas Laureyssens shows pedestrian tracks through an intersection:

Also found several other nice culture and language maps of the US on this site from Valpriaiso University. Many seem to be reprints from US Census reports from 2000, methodology for the others is not clear.
This one shows the largest ancestry group of each county in the US:

This one seems to be more of an anthropological map not sure of the source.

All of these examples seem to highlight different aspects of culture: affiliation (neighborhoods), language use (soda), ancestry, common trajectory and habits. None of these really get at information flow..
UPDATE 2:
Came across (via Political Maps blog) a really great “Patchwork Nation” map/study done by Jim Gimpel and Ann Cizmar from University of Maryland for the Christian Science Monitor/Knight Foundation . They used factor analysis of various demographic data to classify each county into one of 11 categories. Probably the most methodologically sophisticated of the maps on this page. But a shame they didn’t make it possible to see the overlaps in the factors.

The indicators selected for counties were chosen based on their relevance to American politics.
Included are several measures of income, local economic activity, and occupational mix; measures of racial and ethnic composition, and immigration; along with measures of religious adherence at each location for Catholics, evangelical Protestants, Jews, Mormons, and mainline Protestants.
Housing stock indicators were included along with population density, and whether the county was located within a major metropolitan area. We also captured the education level of the population along with recent population growth and migration figures.
We looked at consumer expenditure estimates (measured as a percentage of all household expenditures) for a variety of specific spending categories, including alcohol, tobacco, housing, new vehicle purchase, property taxes, and charitable contributions.
The page on the methodology also includes links to download the data. They also give a good summary of how the dimensionality reduction was done:
We did the factor analysis of the data with standard statistical software, SPSS using varimax rotation. We identified 11 core components, which stood out statistically as best explaining the differences among counties across the wider spectrum of data. In statistical terms, these components explained correlations among the extensive set of county level indicators we used.
After several variables are found to indicate a single underlying component, the principal components procedure produces a factor score, derived from the weighted combination of the variables that are highly associated with that factor. (A factor is a composite index based on combinations of variables such as Hispanic, tobacco spending, and population growth.)
map of emotional density in areas of SF mission district created by people wearing biofeedback monitors, and then narrating a replay of the transcript.
http://www.sf.biomapping.net/map.htm
Another interesting example, via the StrangeMaps blog: various pronunciations in regions of Germany: http://bigthink.com/ideas/26815
The CommonCensus Map project, asks people to name what city they feel closest to, redraws boundaries accordingly: http://www.commoncensus.org/maps.php
Innundated with placenames
http://derekwatkins.wordpress.com/2011/07/25/generic-stream-terms/
Derek Watkins colors streams by generic root names. Probably an interesting overlap of geology and culture.
Eric Fisher’s twitter version of Soda vs. Pop: http://www.flickr.com/photos/walkingsf/6209337794/in/photostream/lightbox/
Here is a version of SF neighborhoods apparently made by clustering Foursquare checkins: http://livehoods.org/maps/sf
Nice UI!
Washington post article and map about american regions: http://www.washingtonpost.com/blogs/govbeat/wp/2013/11/08/which-of-the-11-american-nations-do-you-live-in/