
The field of “information theory” or “communications theory” has as its core concept the idea of the transmission of information as the “reduction of uncertainty” about possible states of the source. The definition is very mathematical and involves very specific concepts of “message,” “encoding,” and the characteristics of the channel of transmission. Even though the formalization is in very mechanistic communications theory terms, the idea of reduction of uncertainty is a powerful tool for describing many information and transmission related phenomena. But there are also other common-use conceptions of information which, at least on the surface, appear unrelated to the communications definition. We often speak of objects as “containing information,” as if it were a kind of liquid which could be poured into a book-shaped container by the author and wrung out drop by drop as the reader pages through it. It may be that speaking of information as if it were a substance is simply a convenient short-hand which makes it possible to avoid the headaches and convolutions necessary to describe information as a time-based communicative process. But it is also true that the classic (Shannon, 1948) definition could simply be too rigid to express the complex shifting semantic meaning systems employed by humans in the processes of perception and communication.
As I understand it, the formal equations of information theory apply to situations in which there is a “source” of information connected to a “receiver” by a “channel” of some finite capacity.
| Fig. 5 Schematic diagram of a general communications system. (copied without permission from Shannon, 1948, p.2) | 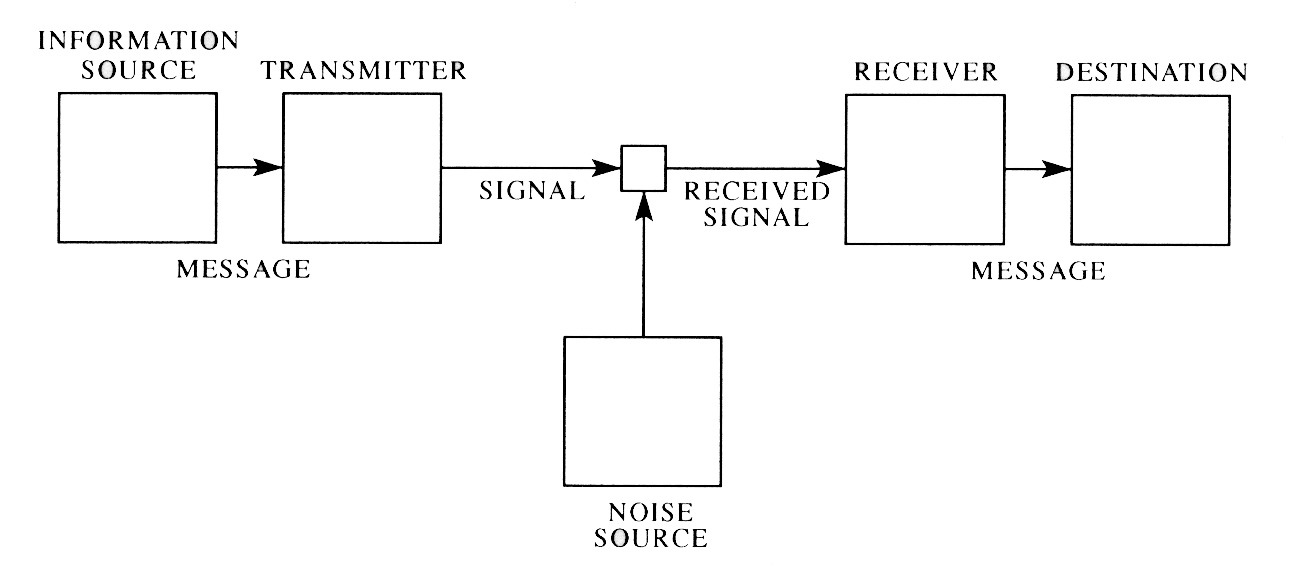 |
The idea is that the source can adopt any of a set of states and the receiver would like to know what state the source is in, but they are unable to perceive each other directly. If no message is transmitted over the channel, the receiver has no information about which state the source is in, and the receiver is in a state of complete uncertainty. If the source could send a message indicating its state, the receiver would know which of the potential states the source had taken, the uncertainty would drop to zero – information transmission would have occurred. The problem is that the state of the source must be expressed in a form which can be carried by the channel. This means that some sort of code must be established by which the receiver can make inferences about the state of the source by examining the state of the channel. It would perhaps be possible for the channel to have as many possible states as the source, but this would mean that the bandwidth or capacity of the channel would have to be tremendous, and the mutually agreed upon code would have to be as complex as the source. In human communication terms, this would mean that there would have to be a symbol or signal for every single meaning that might ever need to be conveyed. However, if the source and receiver agree to consider channel states in groups over time, then the channel can be smaller and the code can be simpler. Rather than needing one channel state for each unique source state, unique groups of channel states from a smaller “alphabet” can be used, and the receiver can determine the state of the source according to the code.
But there are several trade-offs. Messages can no longer be transmitted instantly because time is required to space out the channel states in order to make the groups distinguishable. There is now the possibility of partial or incomplete messages, and the concept of information becomes more meaningful. Because each state of the channel only partially specifies the source’s state, the receiver’s uncertainty is only partially reduced. For example, the source could be trying to transmit an English word one character at time. Initially the receiver has no idea what the word will be. It could be anything in the dictionary, there is complete uncertainty, and no information has been transmitted. Suppose the first letter is sent is “r”. Suddenly the entire dictionary of possible English words is reduced to only those which begin with “r”. There are, of course, a rather large number of English words starting with r, but if the receiver picks one at random, the chances of it being the one the source intended are much better – the uncertainty has been reduced. The source can continue to spell out the word “r” “e” “c” “o” “r” “d” ” ” one letter at a time. Each character has information “associated” with it because it further reduces the number of possible words from which the receiver has to pick. When the final space arrives, the receiver knows exactly which word was being sent.
I used an English word as an example because it immediately points out why it is difficult to directly apply information theory measures outside the realm of signals, compression, and communications technology. (I am, of course, doing great violence to the beauty and precision of Shannon’s definition by recasting it in such vague terms.) The practical problem is that there are several definitions of “record” in the dictionary. It could be either a noun or a verb, and takes on several different meanings depending on its context. More fundamentally, if the source and receiver are actually people trying to communicate, they will have no exact dictionary in common from which the number of potential states could be counted to calculate the uncertainty. In the real world, the definitions of source, channel, code, and receiver are difficult to pin down, seeming to change moment by moment depending on the context, question, and level of analysis. A book can be considered a source of a perceptual message, the channel for communication between the author and the reader, one element in the code of literary culture, and as a partial dictionary for the decoding of its own information.
I think that the concept of reduction of uncertainty can serve as a powerful heuristic for thinking about information. But if we are going to extend the discussion beyond mechanistic communications theory to the diversity of processes involved in the transmission and perception of information between humans, we need much broader and perhaps less formal conception of information. As Umberto Eco states in his A Theory of Semiotics :
Those who reduce semiotics to a theory of communicational acts cannot consider symptoms as signs, nor can they accept as signs any other human behavioral feature from which a receiver infers something about the situation of the sender even though the sender is unaware of sending something to somebody. (Eco 1976, p. 16)
In humans the process of coding, decoding, and pattern detection is amazingly flexible and versatile. We seem to be able to give any object, act, or event meaning and informational properties simply by changing our frame of reference and the context in which we are assembling meaning. The word “record”, for example, now has an additional meaning. It can be used within the context of this text to reference a crude attempt to explain information theory.
Going back to the more formal source-channel-receiver model for a moment, it is interesting to consider the process by which a code could be agreed upon in the first place – how dictionaries are synchronized. Information theory often describes the properties of the source in terms of transition probabilities. That is, all states of the source may not be equally probable, and the chances of a certain state occurring may depend to some degree on the previous states. Essentially what this means is that there may often be a statistically detectable structure to the source’s output. Structure here means that there may be frequency and grammatical properties of the messages which become apparent after enough time has passed or enough messages have been collected for analysis. Even if the receiver knows nothing about the source, the number of potential states, or the coding rules, and must rely entirely on the channel for information, some predictions about the source will soon be possible.
| Fig. 6 Image of a simple Markov graph with three states. Each arrow and its associated number give the probability of the state transition in that direction. Notice that in this example, states C and B have probabilities of repeating, but an A could never be followed by another state A. (after Shannon 1948) | 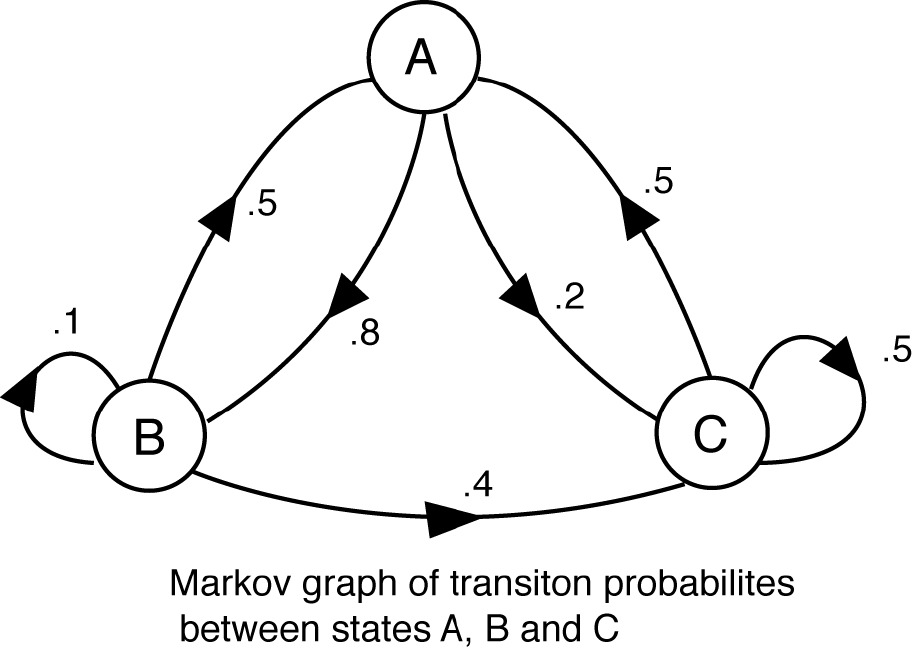 |
This is basically a crude description of a Markov process . (Figure 6) If the receiver keeps a careful count of the messages, it will eventually be possible to construct a table of transition probabilities for each of the states or characters. In other words, if the last character was “A”, what are the odds that the next will be “C”? The idea is that if the source is not just generating noise, there should be detectable patterns to the messages. Some symbols may frequently occur together, (Q and U for example) where others rarely do (X and Z). To use an extended example from Shannon:
To give a visual idea of how this series of processes approaches a language, typical sequences in the approximations to English have been constructed and are given below. In all cases we have assumed a 27-symbol “alphabet,” the 26 letters and a space.
1. Zero-order approximation (symbols independent and equiprobable).
XFOML RXKHRJFFJUJ ZLPWCFWKCYJ FFJEYVKCQSGHYD QPAAMKBZAACIBZLHJQD.
2. First-order approximation (symbols independent but with frequencies of English text).
OCRO HLI RGWR NMIELWIS EU LL NBNESEBYA TH EEI ALHENHTTPA OOBTTVA NAH BRL.
3. Second-order approximation (digram structure as in English).
ON IE ANTSOUTINYS ARE T INCTORE ST BE S DEAMY ACHIN D ILONASIVE TUCOOWE AT TEASONARE FUSO TIZIN ANDY TOBE SEACE CTISBE.
4. Third-order approximation (trigram structure as in English).
IN NO IST LAT WHEY CRATICT FROURE BIRS GROCID PONDENOME OF DEMONSTURES OF THE REPTAGIN IS REGACTIONA OF CRE.
5. First-order word approximation. Rather than continue with tetragram, …n-gram structure it is easier and better to jump at this point to word units. Here words are chosen independently but with their appropriate frequencies.
REPRESENTING AND SPEEDILY IS AN GOOD APT OR COME CAN DIFFERENT NATURAL HERE HE THE AN IN CAME THE TO OF TO EXPERT GRAY COME TO FURNISHES THE LINE MESSAGE HAD BE THESE.
6. Second-order word approximation. The word transition probabilities are correct but no further structure is included.
THE HEAD AND IN FRONTAL ATTACK ON AN ENGLISH WRITER THAT THE CHARACTER OF THIS POINT IS THEREFOR ANOTHER METHOD FOR THE LETTERS THAT THE TIME OF WHO EVER TOLD THE PROBLEM FOR AN UNEXPECTED. (Shannon, 1948, p. 7)
So after a certain amount of time spent observing messages, the receiver may be able to make fairly good predictions about what the next state of the source will be (assuming that the message represents the state of the source). This is interesting for several reasons. A fairly good measure of cumulative information transmission is possible using the perspective of information theory: as the receiver collects more messages, the predictions become more accurate, so the uncertainty is reduced. This means that messages which are “surprising” carry a great deal more information than those which are in line with previous experience.
…since information, subjectively, is measured by changes of probability estimates, what is perfectly predictable contains no information. Those sources in the physical environment which are time-independent and permanent, like buildings, streets and fixtures, after a time will cease to have information for the habitual user of the environment. (Benedikt 1975 p. 85)
For example, if the source has been sending out the text of Shannon’s example 5, the receiver may be operating under the assumption that there are only 21 letters in the in the alphabet. When a word containing Q appears, the receiver will have to revise her assumptions about the number of possible states the source can take. And from a strictly formal standpoint, this may alter the amount of information in previous and future messages because the value of the “change in uncertainty” used to measure information depends on the number of states the systems can take.
So there are several qualities of Shannon’s conception of information which are consistent with a more pragmatic sense of the term. As much as there are patterns in the world, information about the past makes it possible to predict the future. The longer the messages, and the longer the time period of collection, the better the predictions are – more information is known about the source. Yet at the same time, it is possible for extremely short messages, (“Q”) to carry a great deal of information and alter the relevance of previous and future messages. A single message can be the clue which induces a “re-framing” and re-analysis of previous data. In a sense this is the “flash of insight” in social situations when we suddenly reinterpret what we thought was going on or notice the implicit rules we have been playing by: “…one could then see…that the significance of certain deviant acts is that they undermine the intelligibility of everything else we had thought was going on around us.” (Goffman, 1974, p. 5) There is also a sense in which information transfer allows the ability to perceive more states and make finer distinctions among states of the environments. It allows us to acquire increasingly detailed schemas or affordances for interpretation and action. “Knowledge of the environment surely develops as perception develops, extends as the observers travel, gets finer as they learn to scrutinize, gets longer as they apprehend more events, gets fuller as they see more objects, gets richer as they notice more affordances. Knowledge of this sort does not ‘come from’ anywhere; it is got by looking along with listening, feeling, smelling tasting.” (Gibson, 1979, p. 253) That all these various aspects of information might be tightly interdependent is somehow not surprising. Yet clearly something changes when the level of analysis is raised to that of everyday communication and meaning.
Although it may be possible to construct crude models of human communication as a Markov-chain process of character frequencies or conversational states (Thomas, Roger & Bull, 1983) this does not seem to be the level at which humans typically obtain or utilize information and meaning. We seem to be able to deal effectively with letter or word prediction on an unconscious level. This does not mean that we are incapable of dropping to a lower level of analysis if the context or task demands it. We may, for example, be able to locate a person’s accent from a few deviations in vowel pronunciation, or spell check a document if required. But people almost always speak grammatically (at least according to their regional subgroup) and spelling is fairly consistent among literate people. (Myself being case out of point!). So an analysis of letter frequencies usually doesn’t provide us with much information and we tend to gloss over the minutiae. We generally deal with larger units of words, sentence structure, and meaning.9 And, of course, many of our sources of perceptual information cannot be as conveniently chopped up into discrete symbolic units for analysis the way written text can.
There are other approaches possible in a discussion of information. Unpacking the layered meanings and information associated with signs, communication, behavioral acts, perception is often considered the domain of Semiotics. Eco (1976) presents an interesting developing synthesis. His focus is on the attribution of meaning to, and the dynamics of the associations between, signs and symbols in communication. He describes the phenomenon of a symbol’s meaning as occurring like a hierarchical chain of the various potential connotations. The meaning which a symbol or action takes at a certain place or time depends on the context of the instance and the depth of the viewer’s analysis. He points out that contradictory readings of the same sign are often possible – or even co-present in a person’s understanding. Signs often carry with them a sort of ontogenetic history in the form of ghost meanings which reveal themselves on analysis. His emphasis is definitely on meanings as aggregate and continuously changing items.
Metz (1970) has advanced the hypothesis that in every case of communication (except for maybe some rare cases of a very elementary and unequivocal type) we are not dealing with a message but with a text. A text represents the results of the coexistence of many codes (or, at least many sub-codes). (Eco 1976, p. 57)
From his description, meaning seems like something sticky which gets attached to signs each time they are used. If a symbol or action is used in a consistent fashion by a large number of people for some time, there will be a fair amount of consensus as to what it means. But there is still the possibility of any individual giving a sign a new, “less ratified” meaning by using it in a different context with a different intent.
For information transfer to occur, there must be some form of material or energetic contact between communicators. This means that although information is probably not a visible entity in most transmission situations, the behaviors of the people who generate and receive it often are visible. Although the actions taken by individuals in the course of their daily lives may be almost incomprehensibly complex, it is at least possible to imagine crude ways to search for patterns and draw inferences about where information exchange is occurring. In fact, because I’m mostly interested in getting at the properties of information and culture in the context of groups of people, it seems fairly essential for me to look at how some of the structural properties of human relations and communication affect information transmission.
One thought on “Information, Uncertainty, and Meaning”