
Social relations tend to have an amorphous and ephemeral quality, making the term “social structure” at times seem like an oxymoron. Yet it is clear that there are also reoccurring patterns in individuals’ social contacts, and both people and organizations often describe the patterns in terms of fixed relationships. The abstract ties of extended family lineages, social support networks, organized webs of informants, and hierarchical political organizations are frequently spoken of as structures or networks – sets of relations between individuals which may partially predict or explain their behavior. It is often useful to conceptualize these patterns of interaction, friendship, or aid as formal “webs” or “networks” in order to visualize them more completely, compare them, and analyze their properties. A formal network description usually involves delineation of the ties or connections which interrelate a group of individual actors according to some criteria. (Figure 11)
 |
| Fig. 11 An example of a graph of a simple social network and the matrix representation of its connections. Because this is a undirected graph, the matrix is diagonal symmetrical. Two cliques – full connected subgroups – are indicated with circles. A bridging tie is a connection that would break the network into two separate components if it was removed. |
The actual meaning of the ties depends entirely on the data which they represent and the methods used to collect them. Descriptions of networks (“graphs”) with real-valued or directional connections (“edges”) can be used to represent strength relations, like friendship or frequency of interaction, or multiplicity (number of corporate directors in common), or number of academic paper collaborations between two individuals (Newman 2001a). Directionality is often used to include asymmetric relations and reciprocity: A likes B and B likes A, or Mary calls Dave, but not the other way round. Although it is not initially difficult to imagine representing social relations with a formal network description, in actual practice it gets a little dicey. There is a large number of ways in which individuals can be (or not be) related or connected to each other. And each mode of description could potentially generate a different network. In other words, the “picture” of the network of phone calls connecting a particular group of people could be quite different from the reported friendship network, which might even be different from the “true” network of friendships. It is crucial to remain clear that the concept of a social network is an abstract formalism, a tool for analyzing structure by representing relationships in a form which is amenable to computation and descriptive statistics. A social network is different from the network of telephone lines or the national power grid in that there are no literal connections among the actors. Rather the ties in a social network represent shared attributes, interaction probabilities, observed social support, etc. A distinction should also be made between an abstract “collective social network” of actually existing relations, and an individual’s personal concept of it, a “cognitive network.” (Marsden, 1990)
It is often quite difficult to obtain data which can be used to create network descriptions. In some situations there are hard data available (paper citations, telephone call logs), but in many cases the data can only be obtained by asking people questions. This means that the results are subject to all the errors, biases, and interesting quirks of any social science research. For example, people may be unavailable, unwilling to give complete information, unable to accurately recall the parameter of interest, confused by the question, or incapable of giving an objective response. The cognitive representation of a network which is obtained by asking network related questions may not entirely match the actual network under study (Marsden, 1990). Another approach would be to observe people and record the instances of whatever action or interaction is of interest as they occur. This would be feasible if the intention is to describe a small collection of typical “ego-centric” networks, but much more difficult if a snapshot of the full connectivity of a large group is the goal. The distinction between ego-centric and group connectivity (a large collection of overlapping ego networks) descriptions also brings up the bounding problem. If the idea is to get a complete description of possible connections among people, how do you decide where to draw the line around a group of interest? At what number of removes do connections cease to be relevant for the question? Some questions suggest networks that seem to have clearly delineated boundaries – information flow between the working groups of a specific company, for example (Rentsch 1990). But for others, limiting the data to individuals on the company’s payroll might leave out some crucial connections – perhaps one of the chief engineers is sleeping with the CEO’s wife and gets early warning of firings.
Caveats and cautionary conditionals aside, there has been some fascinating work done from a social network perspective with immediate relevance to questions about culture and information transmission. Some of it directly addresses the questions above. Most of the analytical work has been done within the framework of Graph Theory. Many of the properties of ordered lattices, such as percolation of epidemics and path length scaling, have been formally described and analyzed. (Goldenberg, et. al., 2000, Gupta et. al., 2000, Huang, 200, Newman, 1999, Watts, 2000) On the other end of the spectrum, graphs that are completely random (show no recognizable structure or pattern) usually are even easier to deal with analytically. (Callaway et. al., 2000, Friedkin, 1981, Newman, 2000, Rappaport 1953, Rappaport et. al., 1989, Watts 1999) The area in-between, where networks show some structure but also some degree of random connectivity, is much harder to describe formally. Most of the work on “partially-ordered” graphs is done with computer simulation. There has been a recent re-emergence of discussion and work on these “small-world” and other social network problems. (Ahmed & Abdusalam, 2000, Moore & Newman, 2000, Newman, 2000b, Newman & Watts, 1999a, Newman & Watts, 1999b, Stevenson, 1997, Watts, 1999,) Fresh interest may be due partially to recent advances in theoretical tools and computing power, but it is also because of the recognition of related problems in several disciplines – neurons, metabolic pathways, and ecological food webs also form networks.
Ongoing attempts are being made to determine some parameters and graph-theoretic properties of network data collected from human social networks. (Foster et. al., 1961, Klovdahl, 1989, Watts, 1999, ) Although I have not encountered much in the way of conclusive evidence for overarching statements, there does seem to be some consensus about some of their qualitative properties. A great deal of the original research was aimed at establishing the existence of, and hashing out definitions for, sub-groups or cliques within social networks. The terms “clique” or “set” are commonly used by individuals in ordinary conversation in the process of describing or explaining social relations. It appears that there is some empirical basis for the common language practice of dividing groups up into subgroups, but the distinctions are rarely clear cut. Just as in common use, there are always people who don’t quite fit in one category, and the group definitions almost seem to break apart under close inspection. Part of the reason for this may be a confusion of categorical groups defined on the basis of personal attributes (clothing style, academic participation, etc.) and groups defined by actual interaction. But it is also fairly clear that interaction or friendship networks actually do containing various degrees of hierarchically clustered subgroups.
 |
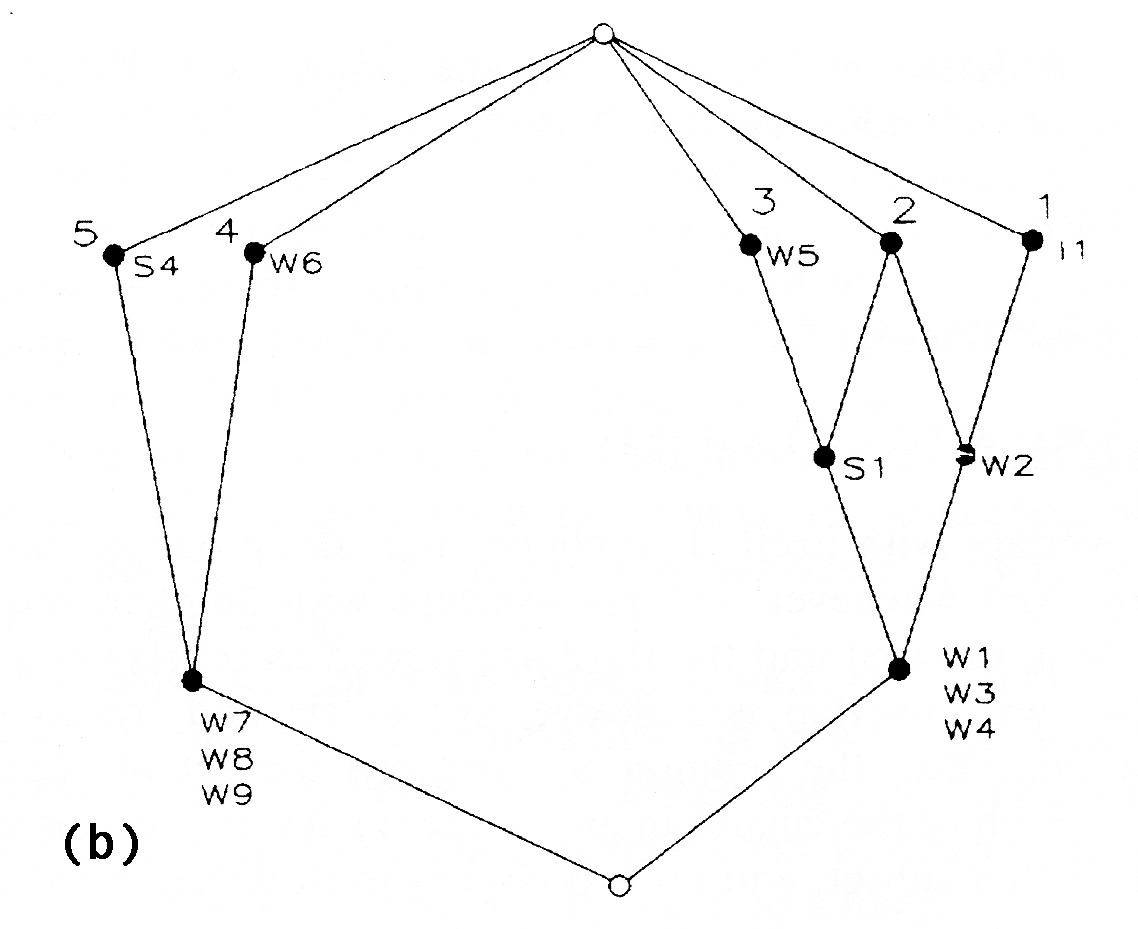 |
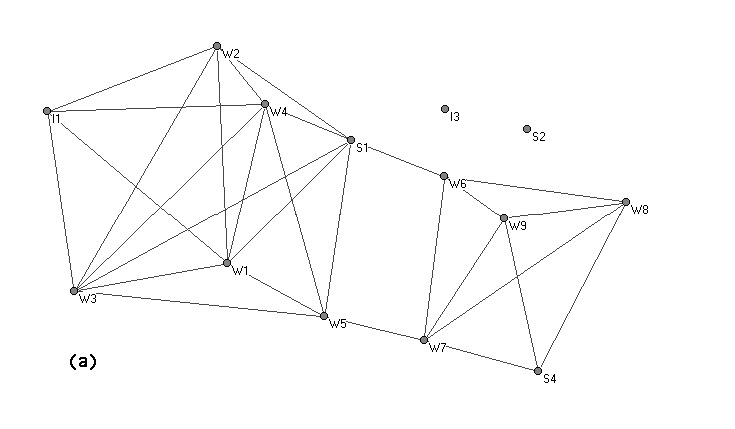
| Fig. 12 Network graph (a) and Galois lattice of cliques (b) for the Roethlisberger and Dixon (1939) observational data on game playing among the workers in the Bank Wiring Room in a Western Electric Company factory. The Galois lattice diagram (b) shows the pattern of overlap in cliques found in the network. The top-most point represents the pair of subsets containing the set of all 12 individuals and no cliques. The bottom-most point represents the pair containing the set of all five cliques and no individuals. (lattice image copied without permission from Freeman 1996) |
In some of the early studies, the networks under consideration were fairly small (~ 20 people) and were derived from co-participation matrices in events or interactions. In his paper on analyzing and visualizing clique structure, Lin Freeman (1996) mentions a study in which several anthropologists recorded incidences of game-playing and conversation between coworkers in the Bank Wiring room in a factory of the Western Electric Company. They13 also recorded their impressions of the structure and functioning of the group and the roles of its various members.
There are many ways of formally defining subgroups in networks. In graph theory, the term “clique” is usually reserved to mean a completely inter-connected sub-group; all of the members of the subgroup are connected to all the other members. In most cases, these formally defined cliques do not correspond well to the common usage sense of the term. It is generally the case that many of the formal cliques present in a graph overlap to a large degree, sharing all but one or two members. This pattern of overlap can be formally analyzed and group structure can be inferred. There are many procedures for doing this, but the general idea is to provide a picture which shows which individuals are present in which groups as the strictness of the definition of the groups is relaxed one step at a time. (Fig. 12) Although the computational tools were not available to the anthropologists at the time of the bank wiring study, Freeman’s subsequent analysis of the hierarchical clique structure arrives at divisions of subgroups which are very close to the impressionistic ones given by the observers at the time of the study.
Another important property of social networks, which also appears to some degree in cluster diagrams, is that of the “bridging tie”. The concept also comes from the intuitive sense that in social networks there are often a few individuals who provide a connection or act as a bridge between structurally separate groups. The idea was well developed, and some of the striking implications were pointed out, in Mark Granovetter’s classic “Strength of Weak Ties” (Granovetter, 1973). To paraphrase his argument: There is a good deal of evidence for strong auto-correlation effects in friendship and acquaintance networks. That is, because of the amount of overlap in fully connected cliques, it is very likely that, not only will most of my friends know each other, most of their friends will be my friends as well. This may mean that we are likely to be present at the same events, share a similar sub-culture, and know similar things. In this kind of situation, individuals who are members of more than one group, or ties which are “weak” but bridge large social distances, may have strong effects because they have access to views or information new to the group: “…weak links are better at spreading information widely, but strong links are better at locally creating the common knowledge.” (Chwe, 1999, p. 128)
The inclusion of this small dose of randomness in the form of long-range connections between tightly clustered sub-graphs can drastically alter the topological properties of a network. One measure which demonstrates this clearly is the scaling of the average graph-theoretic distance between nodes for different sized networks. Graph theory measures the distance between two nodes as the number of intermediate steps necessary to travel from one to the other along the network connections (“edges”). To obtain the average distance for a network with N nodes, a large number of node pairs are chosen at random, the distance between them is calculated, and the results are averaged. This crude measure doesn’t say that much about a specific instance of a network, but if the average distance is calculated for a series of graphs with increasing N and similar topologies, comparisons can be made between different topological classes. For most “regular” topologies (grids, chains, rings, stars, etc.) the average length increases as a roughly linear function of N. But for fully random graphs, the average path length increases only as log(N). (Newman & Watts, 1999, Watts, 1999) And the transition is fairly rapid. Just a small percentage of random connections are enough to noticeably change the scaling curve. (Fig. 13) The reason for this is really pretty intuitive. The greater proportion of random connections or bridging ties there are in a network, the more likely it is that one of my network “neighbors” will not only be a member of my local “neighborhood,” but will also be a member of a neighborhood which would otherwise be at a great distance from me.
| Fig 13 Graph shows the results of a simulation of the effects of different properties of random connections on the average time required for percolation between two randomly chosen nodes. | 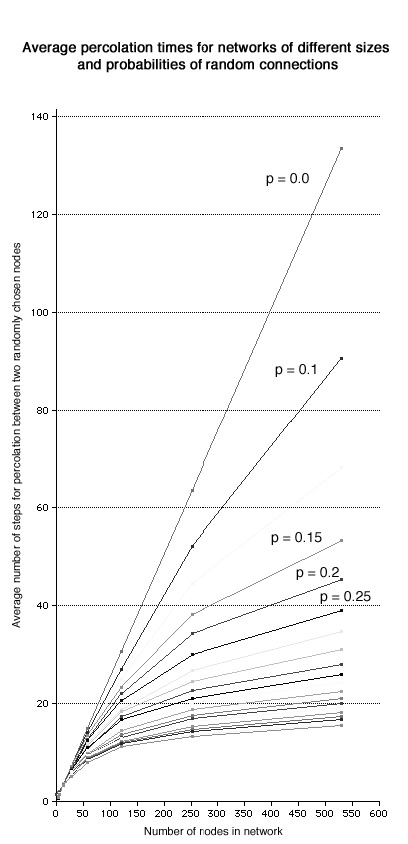 |
This is part of the formal explanation of the “small world” or “six degrees of separation” phenomenon. Although it was probably first brought to the attention of the academic community in a series of striking experiments by Stanley Milgram (Travers & Milgram, 1969), the “small world” idea is something people have been noticing for a some time. Why is it that when meeting someone for the first time it is often possible to discover a mutual friend or acquaintance at some distant (or not so distant) remove? At first this seems rather counter-intuitive, but consider the results of a theoretical percolation or epidemic in a social network. “What is the probability that any two people selected arbitrarily from a large population such as that of United States, will know each other?” Or, a question more relevant to a discussion of transmission, what is the average length of an acquaintance chain connecting two arbitrarily chosen individuals?
Crude estimations of the number of friends and acquaintances of an average individual are on the order of thousands (Watts, 1999 ), where the population of the world is on the order of billions. The random connectivity helps to break the clumpy auto-correlatedness of social groups. But even if social groups are “cliquey” to such a degree that each individual had only 10 friends which were not shared with their correlated group of friends, if each friend sends a message to each of their friends, the message could reach a million people after only six transmission stages. If a message is intentionally rather than passively transmitted, individuals can utilize their knowledge of the networks to shorten chains even further: If I wanted to send a message to an Australian aborigine but didn’t know anyone in Australia, I might first send the message to a friend who had a friend in an embassy, who might pass it to an Australian diplomat…
The theoretical connectivity may not be very consistent with practical considerations. If everyone used social networks rather than the postal service to send messages to aborigines, we’d spend all of our time sending other people’s messages. Any models of rumor or cultural trait transmission must include such attenuating factors as bandwidth restriction (an individual only has a certain amount of time available for communication in a day), various kinds of costs,and of course the myriad possible errors and biases inherent in serial transmission tasks. The small-world properties of social networks make for good anecdotes and provide the potential for clever exploitation in certain circumstances.14 The high effective connectivity may explain why some things spread quickly and thoroughly, but it is also important to consider in more detail the properties of networks which work to prevent total homogenization and diffusion of cultural traits and messages. I’ll discuss this further in the next section
The representations of social networks which most interest me are those in which the ties are real-valued and indicate the relative probability of contact or interaction between individuals. I believe that it is essential to include background levels of noise in the contact model so as to allow for the occurrence of “random” interactions between individuals- neighbors bumping into each other, etc. A network described in this fashion would be “fuzzy” rather than deterministic (Xiaoyan, 1988). Because the relations between people change over time, the conception of an interaction network should be dynamical as well. That is, although networks are commonly visualized as a static “slice”, it is important to be explicit about the time frame the data describe or from which they are aggregated. The question of what parameters control how a social network grows and changes is a fairly open one. One might expect that circumstance, shared culture, personal attractiveness variables, spatial proximity, demographics, work relations, and existing networks would all have some impact. It may be conceptually useful to break apart the various causes, separating out the various “component” networks of forces which act in combination to produce the observed network of interactions.
| Fig. 14 Image illustrates metaphor of the “observed” interaction network as a summation of the effects of various arbitrary classes of structural variables. The grids are intended to represent the matrices of the “slice” networks. The value in the lower left corner, for example, is the sum of the positive and negative effects of the various relational networks above it. | 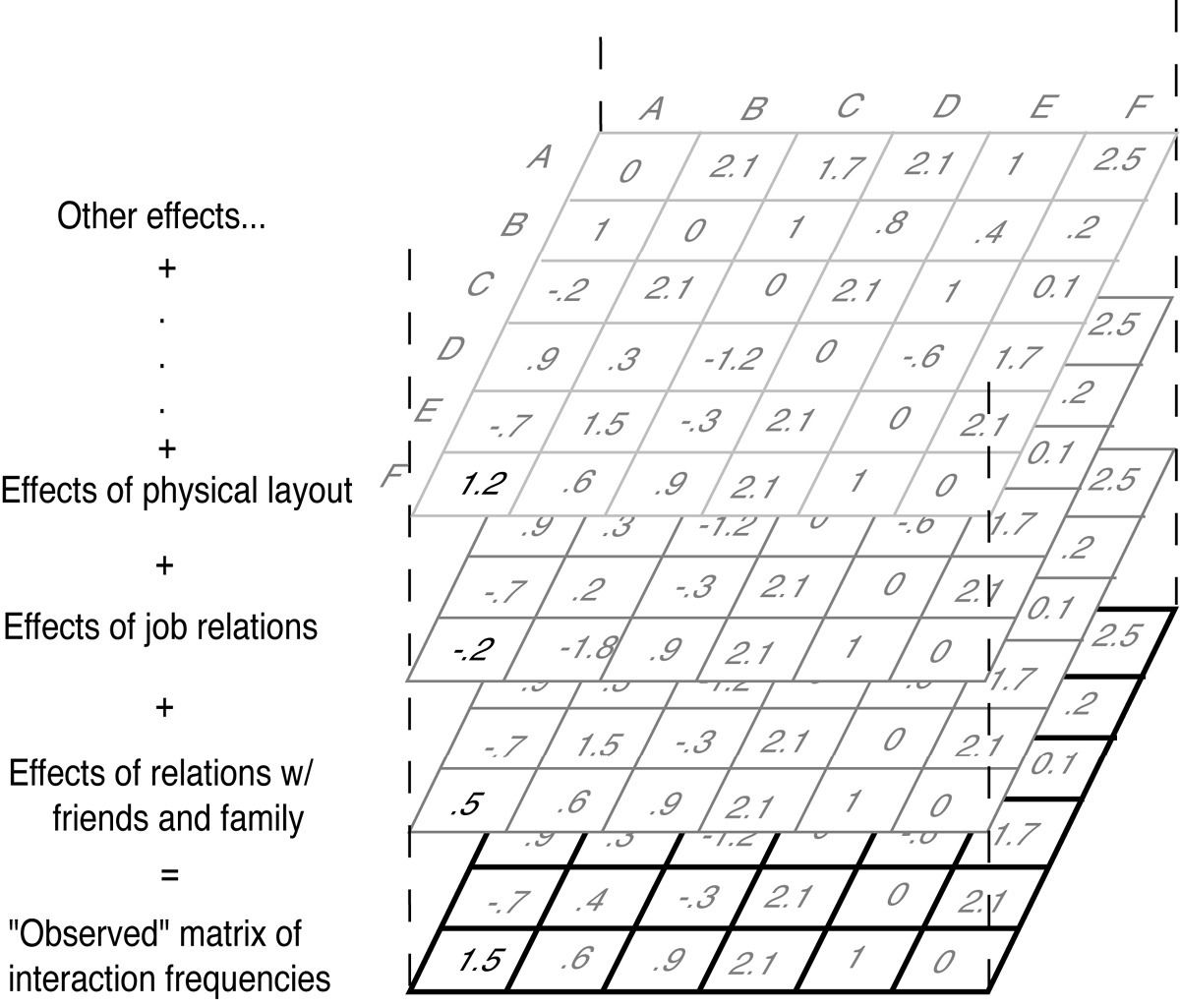 |
One of these “slice” networks might describe the portion of interaction probabilities which are due to spatial proximity. In it individuals who live on the same block will have much stronger ties then those who live in distant cities: “environmental embeddedness.” Another slice might describe the impact of existing relationships on the formation or dissolution of ties (triad balance, etc.). This is, I believe, what is meant by the notion of “structural embeddedness” (Feld, 1997) It would be possible to describe job or institutional structure as one of these slices. An individual who works in a specific capacity may have a formal network of functional relationships, interactions which must occur for them to carry out their assigned tasks but which are essentially independent of who fills the role. These slices and their layered aggregates are really only a means of trying to concretize conceptually the effects of social forces on the relations between individuals. In actual practice they are all interrelated:
Communication, exchange and normative contents of the linkages in social networks are all intermingled in real social institutions for all social interaction involves communication, explicit or implicit, some exchange, and evaluation of behavior in terms of social norms. Whichever we choose to emphasize will depend on the sort of problems we are interested in. (Boissevain & Mitchell, 1973)
Not only do these component networks simultaneously “control” individuals’ behavior, but they may quickly begin to influence and reflect each other. Work- and neighbor-networks may quickly become friendship networks. Antagonistic relations in job situations may cause the actual patterns of communication to diverge radically from the formal organization-chart representation of an institution.
I suggested in the section on cultural transmission that this aggregate contact network, the representation of the actual interactions in which a person has participated, could be used as a crude predictor of cultural transmission. That is, it may be possible to ignore most of the details and content of interaction and simply assume that each time individuals interact some information and cultural traits will be exchanged. Viewed this way, the transmission of a specific item or connotational loading would be probabilistic, but its distribution in a population would, after a period of time, reflect the distribution of interaction probabilities between the members of the population. If, as I’ll discuss in the section on conformity by association, one of the strong measures influencing contact probabilities is the degree of shared culture, then the rate of “transmissibility” of an informational item compared to the rate of change of the network becomes an important consideration.
Swiftly moving items can take advantage of the small world effects and diffuse widely and rapidly. Slower moving cultural traits, like religious or political affiliation, have the potential to alter the shape of interaction networks as they are transmitted. Groups which are initially formed by chance may become stronger as members’ interactions are increasingly biased toward each other – and this might in turn cause increased frequency- dependent effects as the relative number of similar traits increases. The differences in rates of transmission for different items can even be given a probabilistic gloss: A slow moving trait may be one which is composed of a large number of interdependent concepts which must be co-present and integrated before it is usable or detectable. If we still assume that the receiver is trying to assemble all of her incoming information into a coherent whole, but the source is randomly transmitting the elements of the trait (or vice versa), it make take a considerable number of contacts before the receiver can assemble the same message as the source or demonstrator.
It is also possible to take a more fine-grained approach and imagine the interaction network from the perspective of the information being transmitted, rather than individuals’ contact frequencies. Some kinds of information may only be transmitted in certain contexts or with certain pre-conditions. Information which is context dependent may require that interactants share the same context for transmission to occur. Some kinds of confidential work-related information might only be discussed with certain work-mates, for example, so the network as “seen” by a piece of confidential information might be a small subset of that which is seen by an item of gossip about the president. Or to put it another way, each individual may have probabilities of discussing certain topics. For an item or valence to be transmitted between two arbitrarily chosen individuals, they must come into contact (interaction probability) and discuss the topic or context to which the item or schema-component is linked15. If the individuals do not share any of the contexts with which the information is associated, transmission is very unlikely. This might explain why information which is relevant to a large audience is transmitted widely and rapidly. If something can be discussed in many contexts, the likelihood of it getting talked about in a given interaction is much greater- the number of different context-dependent sub-networks which it can be transmitted along is much larger. A good way to visualize this idea of context-dependent networks is to think of the image of a large multidimensional stack of traditional network matrices. As in the example in Figure 14, each slice can show the transmission probabilities for an item which is associated with that context or setting. The actual network of probabilities for a specific item would be the sum of the networks for each of the contexts associated with the item.
14 It would be interesting to consider whether the proliferation of ‘Junk’ email – petitions, bad jokes, rumors – is related to the relative simplicity and low cost of serial transmission tasks in the medium.
15 For an interesting paper on representing the transitions between different ‘modes’ of discourse in dyadic conversations as Markov process, see Thomas, Roger and Bull (1983)